概要
作者: ryan 发布于: 7/14/2025 更新于: 7/14/2025 字数: 0 字 阅读: 0 分钟
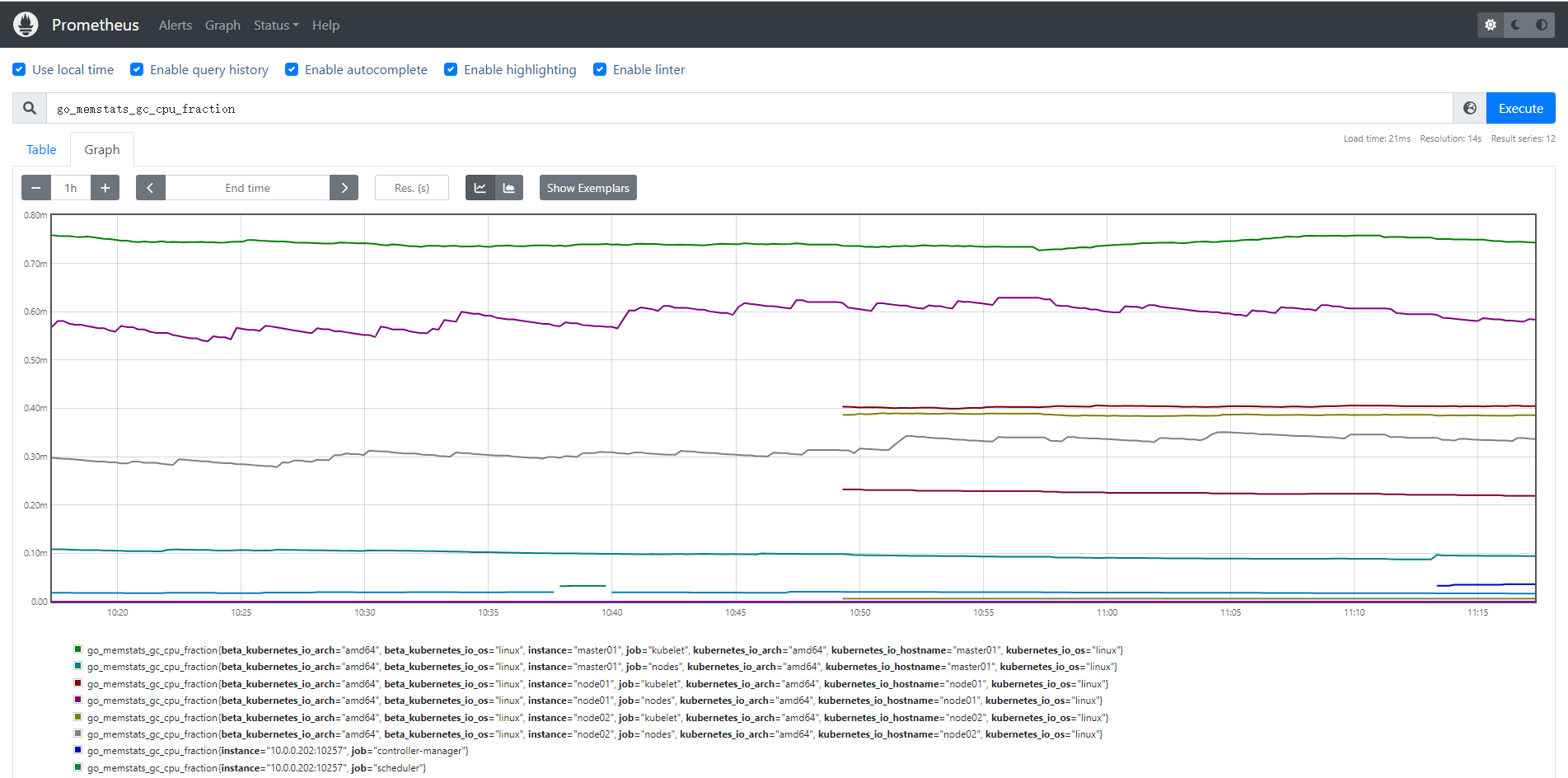
1.自动收集kubelet数据(自带metricsAPI),关键点 HTTPS, CA ,Token (见62篇 )
2.容器监控 cAdvisor (node 上的容器)
3.监控API server (通过kubernetes 的 Service 来获取,用到role 为Endpoints的 ) action: keep 保留符合regex的指标
一、容器监控
说到容器监控我们自然会想到 cAdvisor,我们前面也说过 cAdvisor 已经内置在了 kubelet 组件之中,所以我们不需要单独去安装,cAdvisor 的数据路径为 /api/v1/nodes/<node>/proxy/metrics,但是我们不推荐使用这种方式,因为这种方式是通过 APIServer 去代理访问的,对于大规模的集群比如会对 APIServer 造成很大的压力。
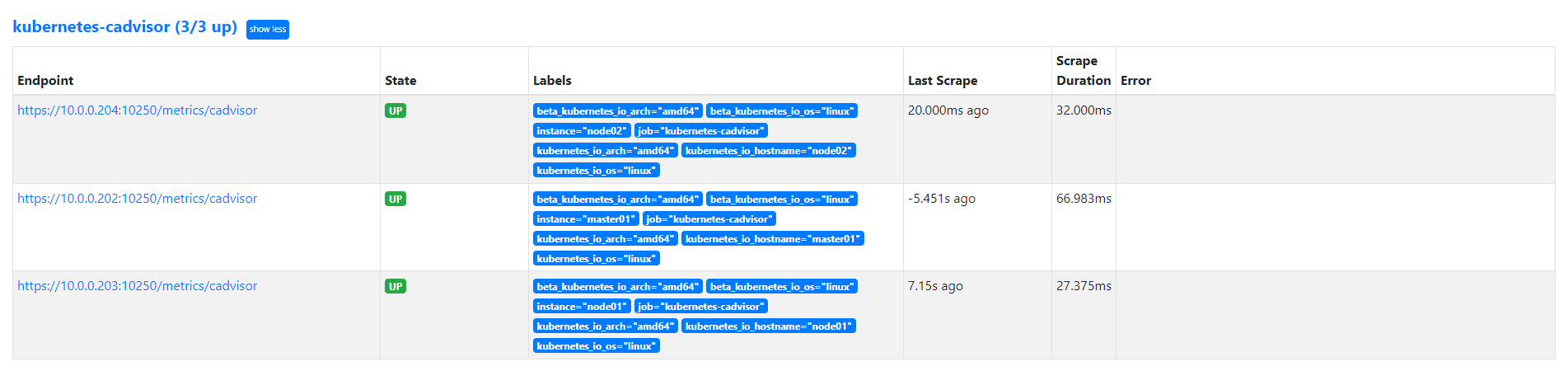
使用node服务发现模式获取 cAdvisor 数据
我们可以直接通过访问 kubelet 的 /metrics/cadvisor 这个路径来获取 cAdvisor 的数据, 同样我们这里使用 node 的服务发现模式,因为每一个节点下面都有 kubelet,自然都有 cAdvisor 采集到的数据指标,配置如下:
- job_name: "kubernetes-cadvisor"
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
replacement: /metrics/cadvisor # <nodeip>/metrics -> <nodeip>/metrics/cadvisor
target_label: __metrics_path__
# 下面的方式不推荐使用
# - target_label: __address__
# replacement: kubernetes.default.svc:443
# - source_labels: [__meta_kubernetes_node_name]
# regex: (.+)
# target_label: __metrics_path__
# replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor上面的配置和我们之前配置 node-exporter 的时候几乎是一样的,区别是我们这里使用了 https 的协议,另外需要注意的是配置了 ca.cart 和 token 这两个文件,这两个文件是 Pod 启动后自动注入进来的,然后加上 __metrics_path__ 的访问路径 /metrics/cadvisor,现在同样更新下配置,然后查看 Targets 路径:
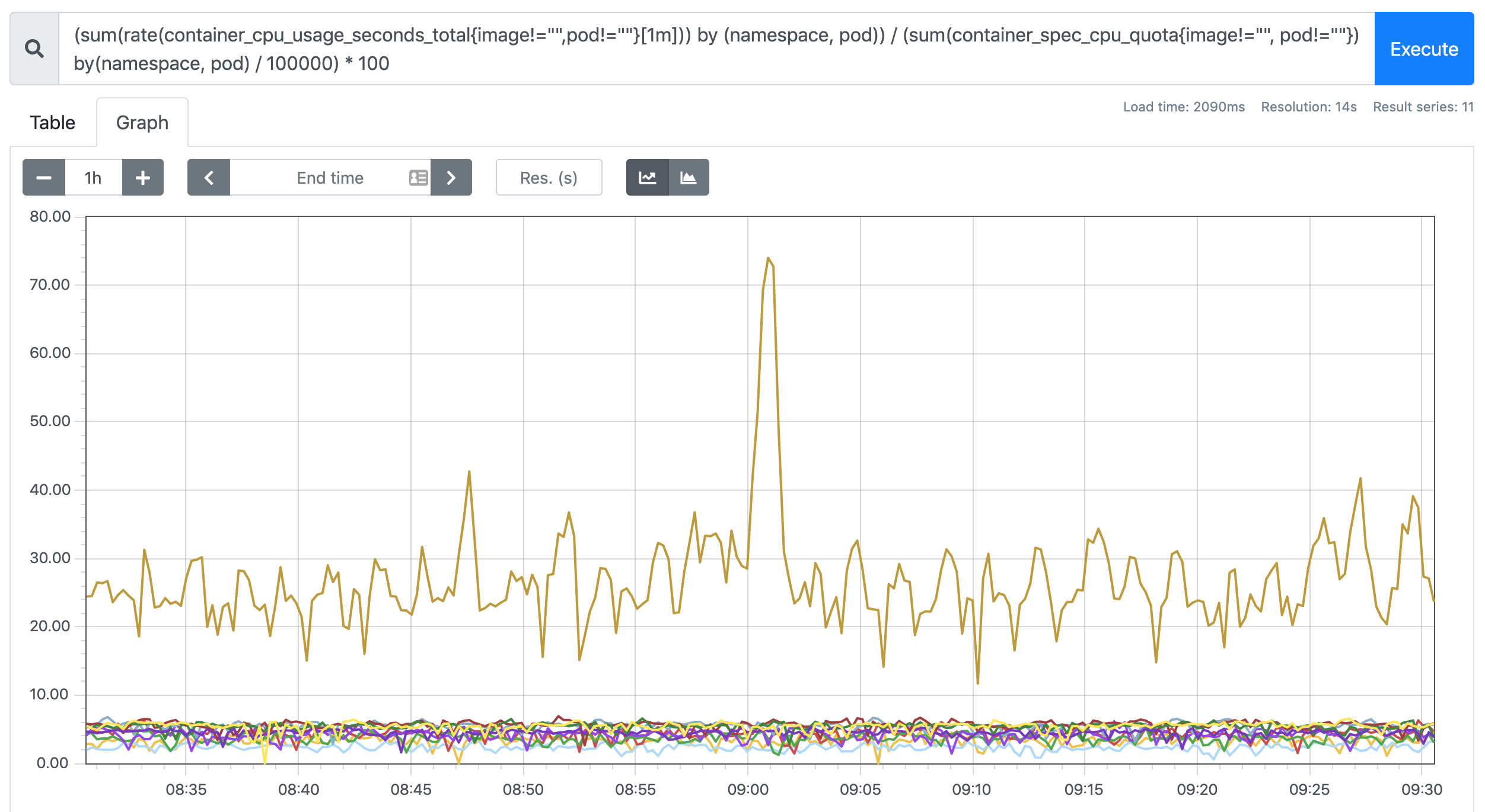
查看Pod CPU使用率
我们可以切换到 Graph 路径下面查询容器相关数据,比如我们这里来查询集群中所有 Pod 的 CPU 使用情况,kubelet 中的 cAdvisor 采集的指标和含义,可以查看 Monitoring cAdvisor with Prometheus 说明,其中有一项:
container_cpu_usage_seconds_total Counter Cumulative cpu time consumed seconds`container_cpu_usage_seconds_total* 是容器累计使用的 CPU 时间,用它除以 CPU 的总时间,就可以得到容器的 CPU 使用率了:
首先计算容器的 CPU 占用时间,由于节点上的 CPU 有多个,所以需要将容器在每个 CPU 上占用的时间累加起来,Pod 在 1m 内累积使用的 CPU 时间为:(根据 pod 和 namespace 进行分组查询)
sum(rate(container_cpu_usage_seconds_total{image!="",pod!=""}[1m])) by (namespace, pod)metrics 在 Kubernetes 1.16 版本中移除了 cadvisor metrics 的 pod_name 和 container_name 这两个标签,改成了 pod 和 container。
然后计算 CPU 的总时间,这里的 CPU 数量是容器分配到的 CPU 数量,container_spec_cpu_quota 是容器的 CPU 配额,它的值是容器指定的 CPU 个数 * 100000,所以 Pod 在 1s 内 CPU 的总时间为:Pod 的 CPU 核数 * 1s:
sum(container_spec_cpu_quota{image!="", pod!=""}) by(namespace, pod) / 100000CPU 配额
由于
container_spec_cpu_quota是容器的 CPU 配额,所以只有配置了 resource-limit CPU 的 Pod 才可以获得该指标数据。
将上面这两个语句的结果相除,就得到了容器的 CPU 使用率:
(sum(rate(container_cpu_usage_seconds_total{image!="",pod!=""}[1m])) by (namespace, pod))
/
(sum(container_spec_cpu_quota{image!="", pod!=""}) by(namespace, pod) / 100000) * 100在 promethues 里面执行上面的 promQL 语句可以得到下面的结果:
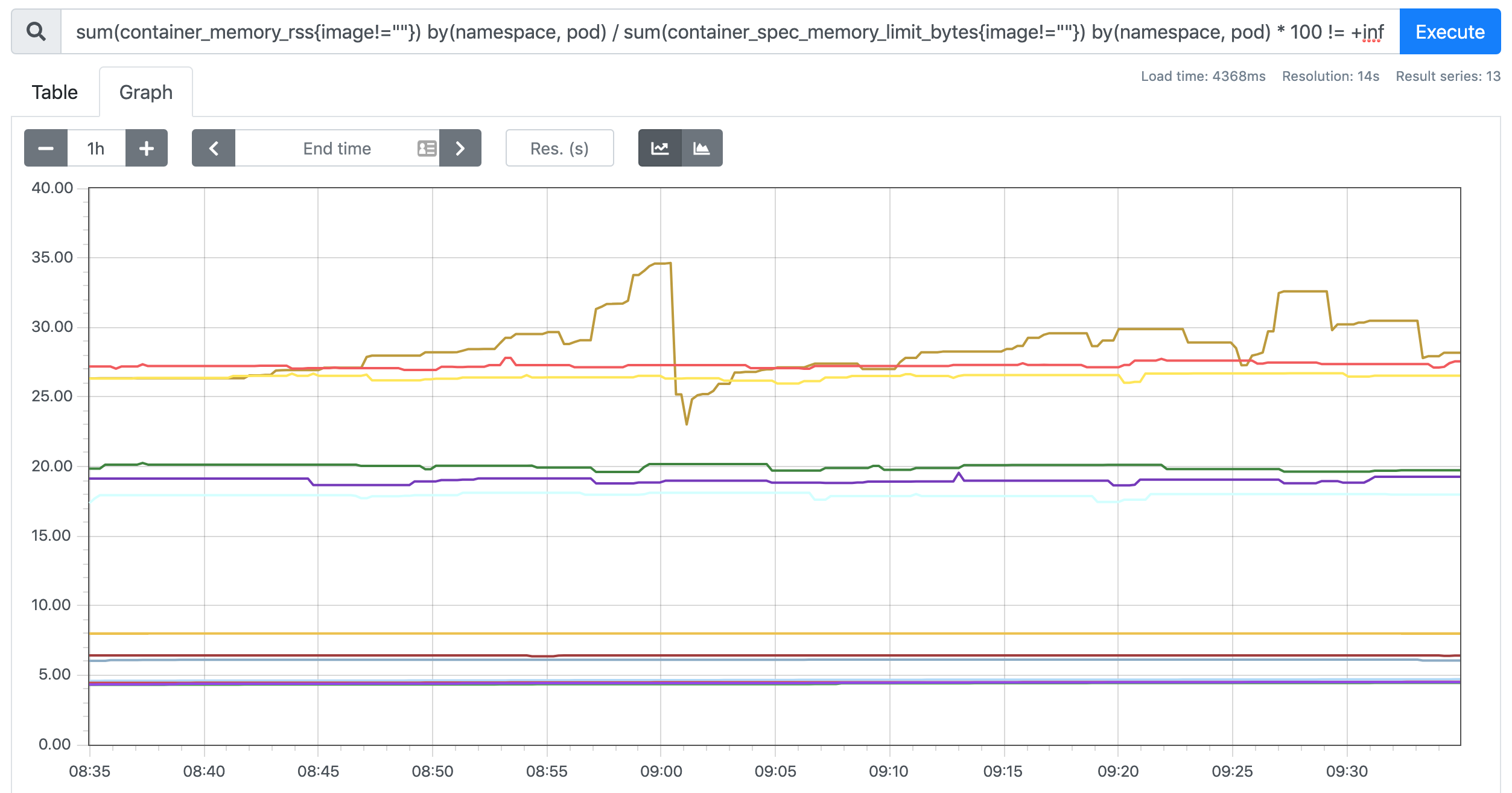
查看Pod 内存使用率
Pod 内存使用率的计算就简单多了,直接用内存实际使用量除以内存限制使用量即可:
sum(container_memory_rss{image!=""}) by(namespace, pod) / sum(container_spec_memory_limit_bytes{image!=""}) by(namespace, pod) * 100 != +inf在 promethues 里面执行上面的 promQL 语句可以得到下面的结果:
二、监控 apiserver
apiserver 作为 Kubernetes 最核心的组件,当然他的监控也是非常有必要的,对于 apiserver 的监控我们可以直接通过 kubernetes 的 Service 来获取:
使用Endpoints自动发现 Service 类型服务
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 33d上面这个 Service 就是我们集群的 apiserver 在集群内部的 Service 地址,要自动发现 Service 类型的服务,我们就需要用到 role 为 Endpoints 的 kubernetes_sd_configs,我们可以在 ConfigMap 对象中添加上一个 Endpoints 类型的服务的监控任务:
- job_name: "kubernetes-apiservers"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_pod_(.+)
replacement: $1
- action: replace
source_labels: [__meta_kubernetes_namespace]
target_label: namespace
regex: (.+)上面这个任务是定义的一个类型为 endpoints 的 kubernetes_sd_configs ,添加到 Prometheus 的 ConfigMap 的配置文件中,然后更新配置:
$ kubectl apply -f prometheus-cm.yaml
configmap/prometheus-config configured
# 隔一会儿执行reload操作
$ curl -X POST "http://10.244.1.6:9090/-/reload"更新完成后,我们再去查看 Prometheus 的 Dashboard 的 target 页面:
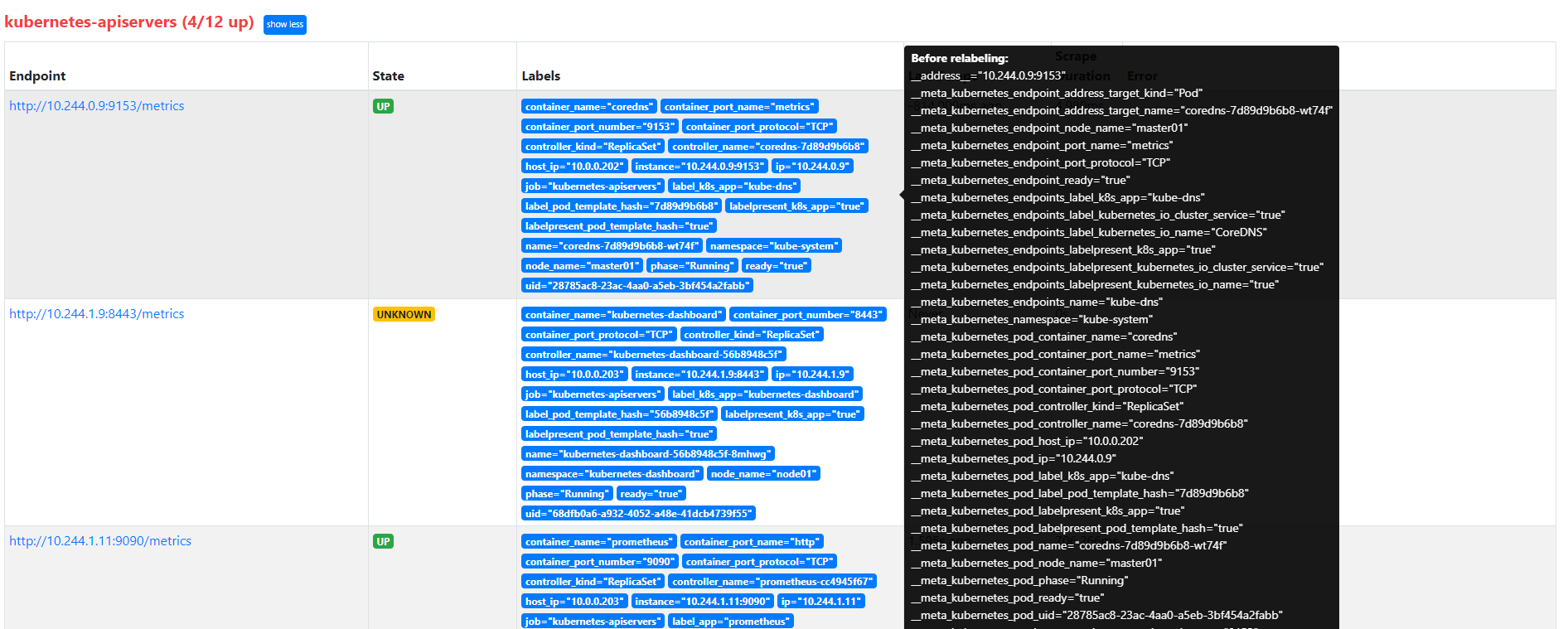
relabel_configs keep过滤
我们可以看到 kubernetes-apiservers 下面出现了很多实例,这是因为这里我们使用的是 Endpoints 类型的服务发现,所以 Prometheus 把所有的 Endpoints 服务都抓取过来了,同样的,上面我们需要的服务名为 kubernetes 这个 apiserver 的服务也在这个列表之中,那么我们应该怎样来过滤出这个服务来呢?
还记得前面的 relabel_configs 吗?没错,同样我们需要使用这个配置,只是我们这里不是使用 replace 这个动作了,而是 keep,就是只把符合我们要求的给保留下来,哪些才是符合我们要求的呢?
我们可以把鼠标放置在任意一个 target 上,可以查看到 Before relabeling里面所有的元数据,比如我们要过滤的服务是 default 这个 namespace 下面,服务名为 kubernetes 的元数据,所以这里我们就可以根据对应的 **__meta_kubernetes_namespace** 和 **__meta_kubernetes_service_name** 这两个元数据来 relabel,另外由于 kubernetes 这个服务对应的端口是 443,需要使用 https 协议,所以这里我们需要使用 https 的协议,对应的就需要将 ca 证书配置上,如下所示:
- job_name: "kubernetes-apiservers"
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels:
[
__meta_kubernetes_namespace,
__meta_kubernetes_service_name,
__meta_kubernetes_endpoint_port_name,
]
action: keep
regex: default;kubernetes;https现在重新更新配置文件、重新加载 Prometheus,切换到 Prometheus 的 Targets 路径下查看:

现在可以看到 kubernetes-apiserver 这个任务下面只有 apiserver 这一个实例了,证明我们的 relabel 是成功的,现在我们切换到 Graph 路径下面查看下采集到的数据,比如查询 apiserver 的总的请求数:
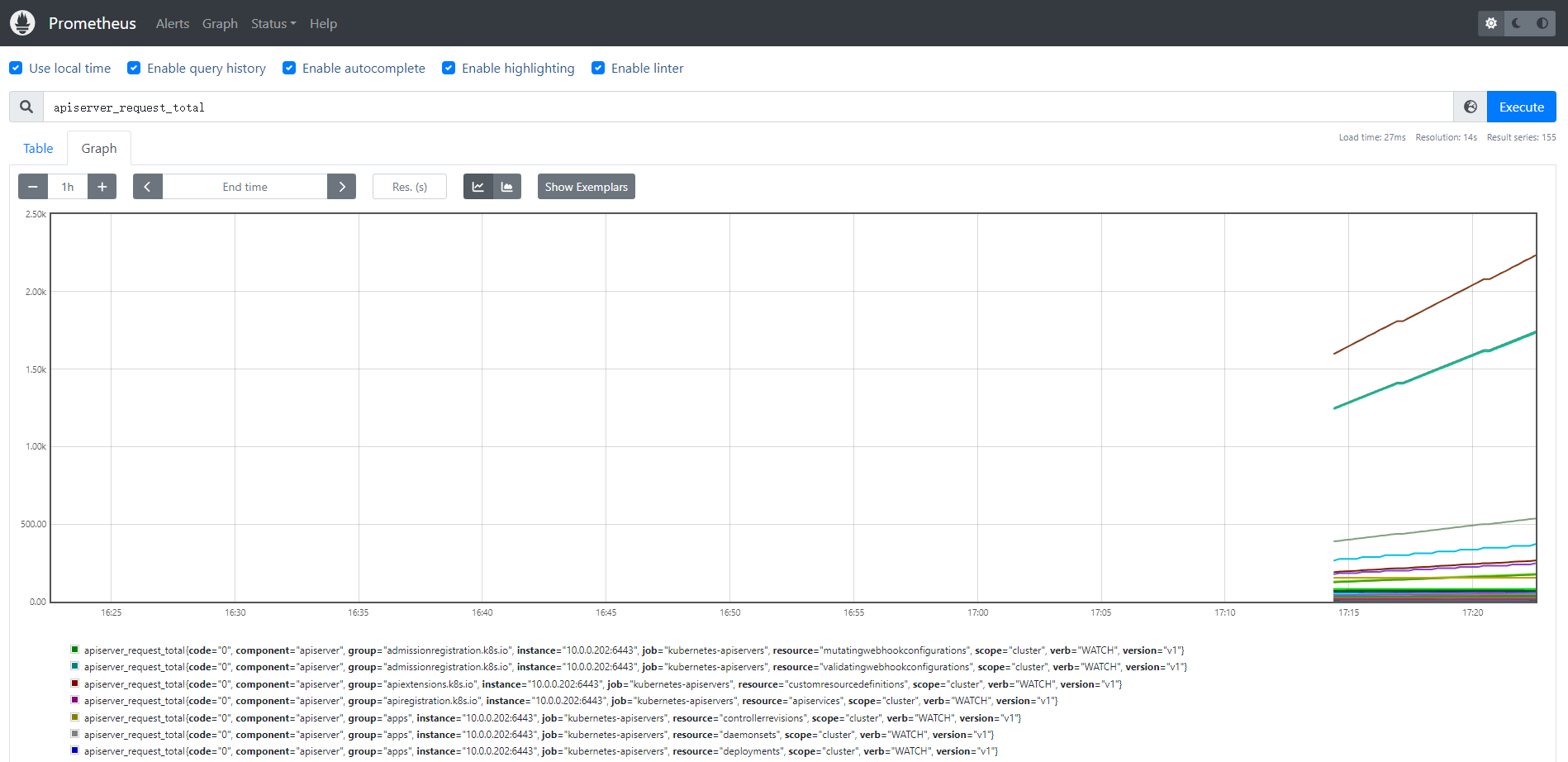
这样我们就完成了对 Kubernetes APIServer 的监控。
另外如果我们要来监控其他系统组件,比如 kube-controller-manager、kube-scheduler 的话应该怎么做呢?
监控kube-scheduler
https://zhuanlan.zhihu.com/p/601866823
https://blog.csdn.net/qq_43164571/article/details/119990724
curl -ik https://master节点的ip地址:10259
root@master01:/etc/kubernetes# curl -k https://10.0.0.202:10259/healthz
okroot@master01:/etc/kubernetes#修改kube-scheduler监听地址
如果 master 节点的 10257 / 10259 端口不可访问,并且使用 kubeadm 安装集群,请修改 /etc/kubernetes/manifests/kube-controller-manager.yaml 文件和 /etc/kubernetes/manifests/kube-scheduler.yaml 文件,将其中的 - --bind-address=127.0.0.1 修改为 - --bind-address=0.0.0.0
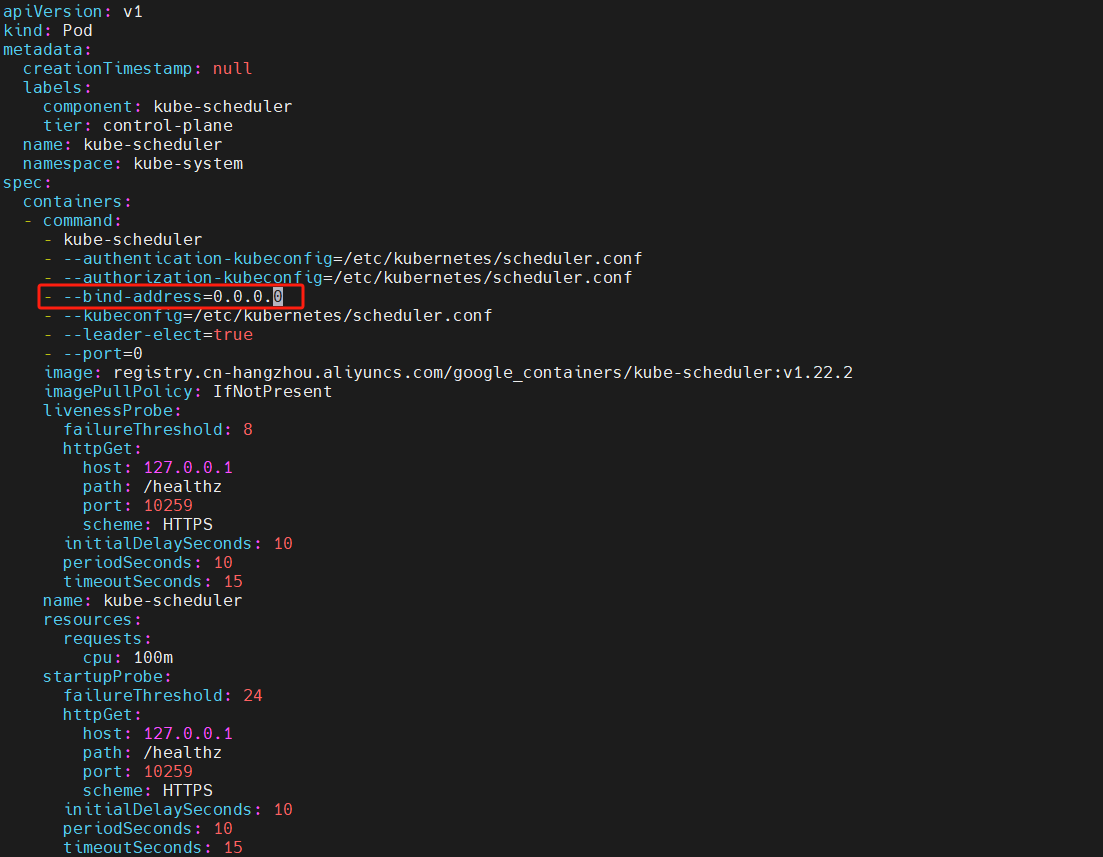
由于manifests目录下是以静态Pod运行在集群中的,所以只要修改静态Pod目录下对应的yaml文件即可。
等待一会后,对应服务会自动重启,所以不需要我们手动重启。
创建Endpoint
当使用 Prometheus 监控 Kubernetes 中的服务时,一种常见的做法是使用 Kubernetes 服务发现机制来自动发现和监控服务(<u>role: endpoints</u>是指定 Kubernetes 服务发现的角色,即告诉 Prometheus 使用 Endpoints API 来发现服务。)对于一些内部组件如 kube-scheduler, kube-controller-manager** **在 Kubernetes 中并没有直接暴露的 Endpoints,因此需要手动创建一个 Service 对象来模拟这个组件的 Endpoints,以便 Prometheus 可以通过 endpoint 模式进行服务发现和监控。
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: https
port: 10259
targetPort: 10259
protocol: TCP查看Endpoints
$ kubectl get endpoints -n kube-system
NAME ENDPOINTS AGE
kube-dns 10.244.0.10:53,10.244.0.11:53,10.244.0.10:53 + 3 more... 5d22h
kube-scheduler 10.0.0.202:10259 3m12s采集配置
- job_name: 'scheduler'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-scheduler;https匹配规则(通过 relabel_configs 的 keep 实现)
endpoint 的 namespace 要求是 kube-system
name 要求是 kube-scheduler
endpoint 的 port_name 要求是叫 https
查看数据

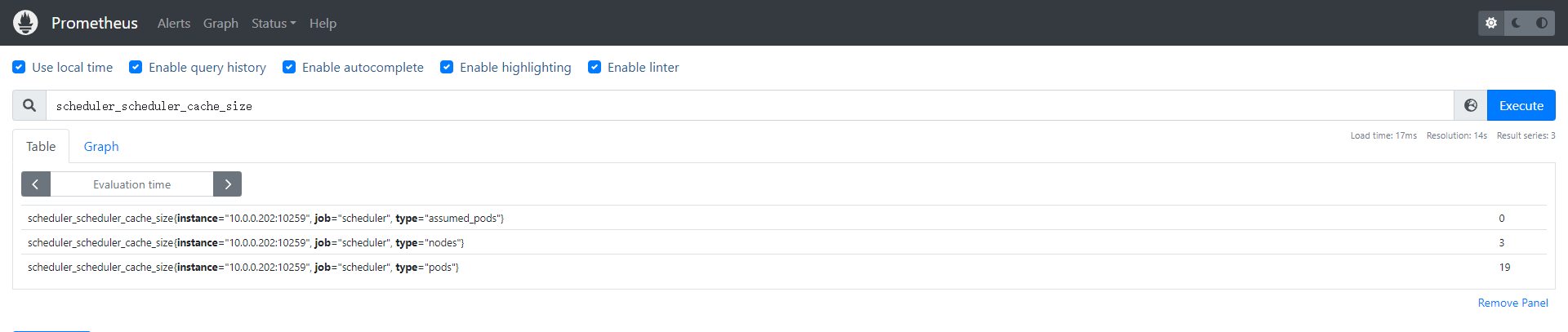
监控 kube-controller-manager
修改**kube-controller-manager **监听地址
#curl -ik https://master节点的ip地址:10259
$ curl -ik https://10.0.0.202:10257/healthz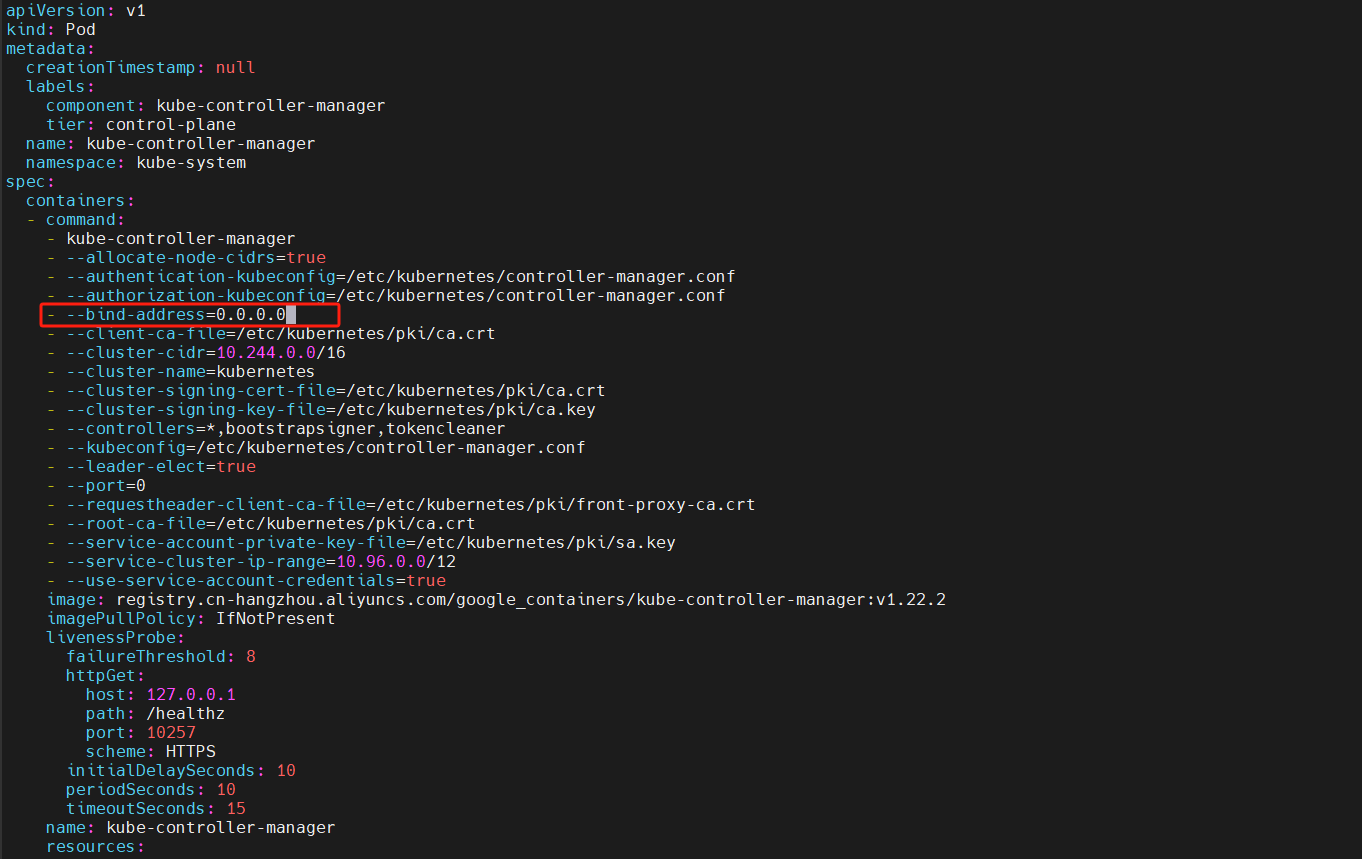
创建Endpoint
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: https
port: 10257
targetPort: 10257
protocol: TCP$ kubectl get endpoints -n kube-system
NAME ENDPOINTS AGE
kube-controller-manager 10.0.0.202:10257 62s
kube-dns 10.244.0.10:53,10.244.0.11:53,10.244.0.10:53 + 3 more... 5d23h
kube-scheduler 10.0.0.202:10259 61m采集配置
- job_name: 'controller-manager'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
insecure_skip_verify: true
authorization:
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-controller-manager;https查看数据