亲合性调度
作者: ryan 发布于: 8/17/2025 更新于: 8/17/2025 字数: 0 字 阅读: 0 分钟
一般情况下我们部署的 Pod 是通过集群的自动调度策略来选择节点的,默认情况下调度器考虑的是资源足够,并且负载尽量平均,但是有的时候我们需要能够更加细粒度的去控制 Pod 的调度,比如我们希望一些机器学习的应用只跑在有 GPU 的节点上;但是有的时候我们的服务之间交流比较频繁,又希望能够将这服务的 Pod 都调度到同一个的节点上。
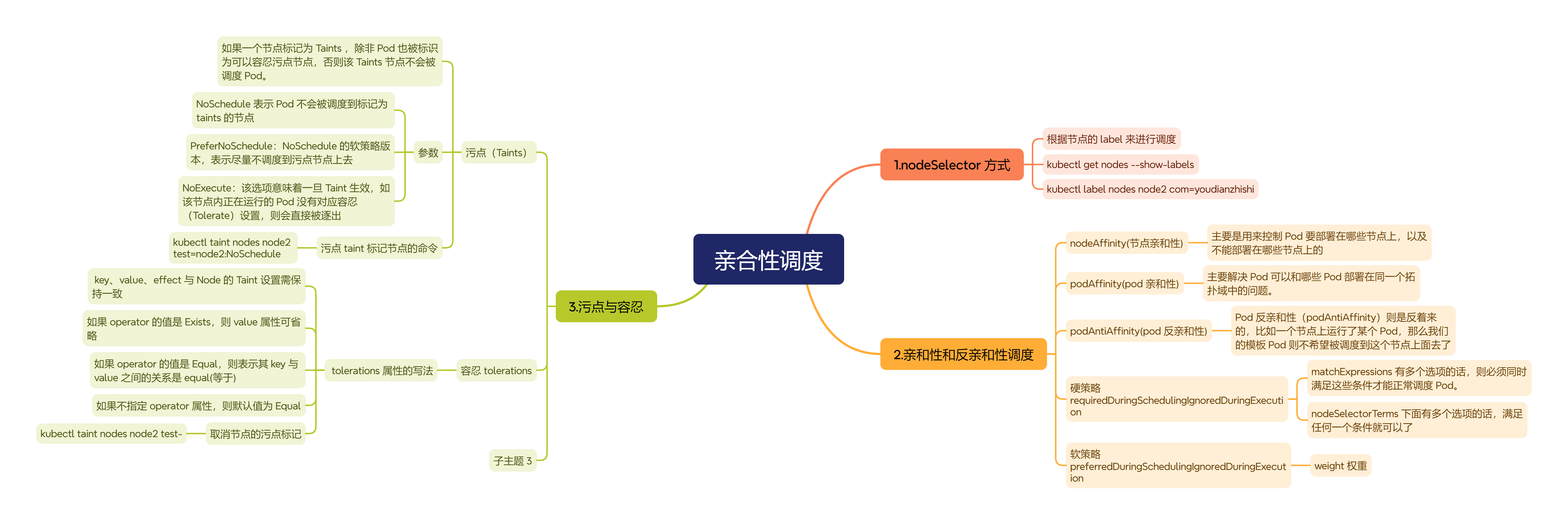
这就需要使用一些调度方式来控制 Pod 的调度了,主要有两个概念:亲和性和反亲和性,亲和性又分成节点亲和性(nodeAffinity)和 Pod 亲和性(podAffinity)。
nodeSelector
在了解亲和性之前,我们先来了解一个非常常用的调度方式:nodeSelector。
我们知道 label 标签是 kubernetes 中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,比如最常见的 Service 对象通过 label 去匹配 Pod 资源,而 Pod 的调度也可以根据节点的 label 来进行调度。
我们可以通过下面的命令查看我们的 node 的 label:
$ kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master1 Ready control-plane,master 82d v1.22.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
node1 Ready <none> 82d v1.22.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux
node2 Ready <none> 82d v1.22.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux现在我们先给节点 node2 增加一个com=youdianzhishi的标签,命令如下:
$ kubectl label nodes node2 com=youdianzhishi
node/node2 labeled我们可以通过上面的 --show-labels 参数可以查看上述标签是否生效。当节点被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在 Pod 的 spec 字段中添加 nodeSelector 字段,里面是我们需要被调度的节点的 label 标签。
比如,下面的 Pod 我们要强制调度到 node2 这个节点上去,我们就可以使用 nodeSelector 来表示了:
# node-selector-demo.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
app: busybox-pod
name: test-busybox
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
imagePullPolicy: Always
name: test-busybox
nodeSelector:
com: youdianzhishi我们可以通过 describe 命令查看调度结果:
$ kubectl apply -f pod-selector-demo.yaml
pod/test-busybox created
$ kubectl describe pod test-busybox
Name: test-busybox
Namespace: default
Priority: 0
Node: node2/192.168.31.46
......
Node-Selectors: com=youdianzhishi
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled <unknown> default-scheduler Successfully assigned default/test-busybox to node2
Normal Pulling 13s kubelet, node2 Pulling image "busybox"
Normal Pulled 10s kubelet, node2 Successfully pulled image "busybox"
Normal Created 10s kubelet, node2 Created container test-busybox
Normal Started 9s kubelet, node2 Started container test-busybox我们可以看到 Events 下面的信息,我们的 Pod 通过默认的 default-scheduler 调度器被绑定到了 node2 节点。
不过需要注意的是nodeSelector 属于强制性的,如果我们的目标节点没有可用的资源,我们的 Pod 就会一直处于 Pending 状态。
通过上面的例子我们可以感受到 nodeSelector 的方式比较直观,但是还够灵活,控制粒度偏大,接下来我们再和大家了解下更加灵活的方式:节点亲和性(nodeAffinity)。
亲和性和反亲和性调度
前面我们了解了 kubernetes 调度器的调度流程,我们知道默认的调度器在使用的时候,经过了 predicates 和 priorities 两个阶段,但是在实际的生产环境中,往往我们需要根据自己的一些实际需求来控制 Pod 的调度,这就需要用到 nodeAffinity(节点亲和性)、podAffinity(pod 亲和性) 以及 podAntiAffinity(pod 反亲和性)。
亲和性调度可以分成软策略和硬策略两种方式:
- 软策略就是如果现在没有满足调度要求的节点的话,Pod 就会忽略这条规则,继续完成调度过程,说白了就是满足条件最好了,没有的话也无所谓
- 硬策略就比较强硬了,如果没有满足条件的节点的话,就不断重试直到满足条件为止,简单说就是你必须满足我的要求,不然就不干了
对于亲和性和反亲和性都有这两种规则可以设置: preferredDuringSchedulingIgnoredDuringExecution 和requiredDuringSchedulingIgnoredDuringExecution,前面的就是软策略,后面的就是硬策略。
节点亲和性
节点亲和性(nodeAffinity)主要是用来控制 Pod 要部署在哪些节点上,以及不能部署在哪些节点上的,它可以进行一些简单的逻辑组合了,不只是简单的相等匹配。
比如现在我们用一个 Deployment 来管理8个 Pod 副本,现在我们来控制下这些 Pod 的调度,如下例子:
# node-affinity-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: node-affinity
labels:
app: node-affinity
spec:
replicas: 8
selector:
matchLabels:
app: node-affinity
template:
metadata:
labels:
app: node-affinity
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
name: nginxweb
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- master1
preferredDuringSchedulingIgnoredDuringExecution: # 软策略
- weight: 1
preference:
matchExpressions:
- key: com
operator: In
values:
- youdianzhishi上面这个 Pod 首先是要求不能运行在 master1 这个节点上,如果有个节点满足 com=youdianzhishi 的话就优先调度到这个节点上。
由于上面 node02 节点我们打上了 com=youdianzhishi 这样的 label 标签,所以按要求会优先调度到这个节点来的,现在我们来创建这个 Pod,然后查看具体的调度情况是否满足我们的要求。
$ kubectl apply -f node-affinty-demo.yaml
deployment.apps/node-affinity created
$ kubectl get pods -l app=node-affinity -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-cdd9d54d9-bgbbh 1/1 Running 0 2m28s 10.244.2.247 node2 <none> <none>
node-affinity-cdd9d54d9-dlbck 1/1 Running 0 2m28s 10.244.4.16 node1 <none> <none>
node-affinity-cdd9d54d9-g2jr6 1/1 Running 0 2m28s 10.244.4.17 node1 <none> <none>
node-affinity-cdd9d54d9-gzr58 1/1 Running 0 2m28s 10.244.1.118 node1 <none> <none>
node-affinity-cdd9d54d9-hcv7r 1/1 Running 0 2m28s 10.244.2.246 node2 <none> <none>
node-affinity-cdd9d54d9-kvxw4 1/1 Running 0 2m28s 10.244.2.245 node2 <none> <none>
node-affinity-cdd9d54d9-p4mmk 1/1 Running 0 2m28s 10.244.2.244 node2 <none> <none>
node-affinity-cdd9d54d9-t5mff 1/1 Running 0 2m28s 10.244.1.117 node2 <none> <none>从结果可以看出有5个 Pod 被部署到了 node2 节点上,但是可以看到并没有一个 Pod 被部署到 master1 这个节点上,因为我们的硬策略就是不允许部署到该节点上,而 node2 是软策略,所以会尽量满足。这里的匹配逻辑是 label 标签的值在某个列表中,现在 Kubernetes 提供的操作符有下面的几种:
In:label 的值在某个列表中
NotIn:label 的值不在某个列表中
Gt:label 的值大于某个值
Lt:label 的值小于某个值
Exists:某个 label 存在
DoesNotExist:某个 label 不存在但是需要注意的是如果 nodeSelectorTerms 下面有多个选项的话,满足任何一个条件就可以了;如果 matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 Pod。
Pod 亲和性
Pod 亲和性(podAffinity)主要解决 Pod 可以和哪些 Pod 部署在同一个拓扑域中的问题(其中拓扑域用主机标签实现,可以是单个主机,也可以是多个主机组成的 cluster、zone 等等),而 Pod 反亲和性主要是解决 Pod 不能和哪些 Pod 部署在同一个拓扑域中的问题,它们都是处理的 Pod 与 Pod 之间的关系,比如一个 Pod 在一个节点上了,那么我这个也得在这个节点,或者你这个 Pod 在节点上了,那么我就不想和你待在同一个节点上。
由于我们这里只有一个集群,并没有区域或者机房的概念,所以我们这里直接使用主机名来作为拓扑域,把 Pod 创建在同一个主机上面。
$ kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
master1 Ready control-plane,master 82d v1.22.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master1,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
node1 Ready <none> 82d v1.22.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node1,kubernetes.io/os=linux
node2 Ready <none> 82d v1.22.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node2,kubernetes.io/os=linux,com=youdianzhishi同样,还是针对上面的资源对象,我们来测试下 Pod 的亲和性:
# pod-affinity-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-affinity
labels:
app: pod-affinity
spec:
replicas: 3
selector:
matchLabels:
app: pod-affinity
template:
metadata:
labels:
app: pod-affinity
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: nginxweb
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- busybox-pod
topologyKey: kubernetes.io/hostname上面这个例子中的 Pod 需要调度到某个指定的节点上,并且该节点上运行了一个带有 app=busybox-pod 标签的 Pod。
我们可以查看有标签 app=busybox-pod 的 pod 列表:
$ kubectl get pods -l app=busybox-pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-busybox 1/1 Running 0 27m 10.244.2.242 node2 <none> <none>我们看到这个 Pod 运行在了 node2 的节点上面,所以按照上面的亲和性来说,上面我们部署的3个 Pod 副本也应该运行在 node2 节点上:
$ kubectl apply -f pod-affinity-demo.yaml
deployment.apps/pod-affinity created
$ kubectl get pods -o wide -l app=pod-affinity
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-587f9b5b58-5nxmf 1/1 Running 0 26s 10.244.2.249 node2 <none> <none>
pod-affinity-587f9b5b58-m2j7s 1/1 Running 0 26s 10.244.2.248 node2 <none> <none>
pod-affinity-587f9b5b58-vrd7b 1/1 Running 0 26s 10.244.2.250 node2 <none> <none>如果我们把上面的 test-busybox 和 pod-affinity 这个 Deployment 都删除,然后重新创建 pod-affinity 这个资源,看看能不能正常调度呢:
$ kubectl delete -f node-selector-demo.yaml
pod "test-busybox" deleted
$ kubectl delete -f pod-affinity-demo.yaml
deployment.apps "pod-affinity" deleted
$ kubectl apply -f pod-affinity-demo.yaml
deployment.apps/pod-affinity created
$ kubectl get pods -o wide -l app=pod-affinity
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-587f9b5b58-bbfgr 0/1 Pending 0 18s <none> <none> <none> <none>
pod-affinity-587f9b5b58-lwc8n 0/1 Pending 0 18s <none> <none> <none> <none>
pod-affinity-587f9b5b58-pc7ql 0/1 Pending 0 18s <none> <none> <none> <none>我们可以看到都处于 Pending 状态了,这是因为现在没有一个节点上面拥有 app=busybox-pod 这个标签的 Pod,而上面我们的调度使用的是硬策略,所以就没办法进行调度了,大家可以去尝试下重新将 test-busybox 这个 Pod 调度到其他节点上,观察下上面的3个副本会不会也被调度到对应的节点上去。
我们这个地方使用的是 kubernetes.io/hostname 这个拓扑域,意思就是我们当前调度的 Pod 要和目标的 Pod 处于同一个主机上面,因为要处于同一个拓扑域下面,为了说明这个问题,我们把拓扑域改成 beta.kubernetes.io/os,同样的我们当前调度的 Pod 要和目标的 Pod 处于同一个拓扑域中,目标的 Pod 是拥有 beta.kubernetes.io/os=linux 的标签,而我们这里所有节点都有这样的标签,这也就意味着我们所有节点都在同一个拓扑域中,所以我们这里的 Pod 可以被调度到任何一个节点,重新运行上面的 app=busybox-pod 的 Pod,然后再更新下我们这里的资源对象:
$ kubectl get pods -o wide -l app=pod-affinity
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity-76c56567c-792n4 1/1 Running 0 2m59s 10.244.2.254 node2 <none> <none>
pod-affinity-76c56567c-8s2pd 1/1 Running 0 3m53s 10.244.4.18 node1 <none> <none>
pod-affinity-76c56567c-hx7ck 1/1 Running 0 2m52s 10.244.3.23 node2 <none> <none>可以看到现在是分别运行在2个节点下面的,因为他们都属于 beta.kubernetes.io/os 这个拓扑域。
Pod 反亲和性
Pod 反亲和性(podAntiAffinity)则是反着来的,比如一个节点上运行了某个 Pod,那么我们的模板 Pod 则不希望被调度到这个节点上面去了。
我们把上面的 podAffinity 直接改成 podAntiAffinity:
# pod-antiaffinity-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: pod-antiaffinity
labels:
app: pod-antiaffinity
spec:
replicas: 3
selector:
matchLabels:
app: pod-antiaffinity
template:
metadata:
labels:
app: pod-antiaffinity
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: nginxweb
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- busybox-pod
topologyKey: kubernetes.io/hostname这里的意思就是如果一个节点上面有一个 app=busybox-pod 这样的 Pod 的话,那么我们的 Pod 就别调度到这个节点上面来,上面我们把app=busybox-pod 这个 Pod 固定到了 node2 这个节点上面的,所以正常来说我们这里的 Pod 不会出现在该节点上:
$ kubectl apply -f pod-antiaffinity-demo.yaml
deployment.apps/pod-antiaffinity created
$ kubectl get pods -l app=pod-antiaffinity -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-antiaffinity-84d5bf9df4-9c9qk 1/1 Running 0 73s 10.244.4.19 node1 <none> <none>
pod-antiaffinity-84d5bf9df4-q6lkm 1/1 Running 0 67s 10.244.3.24 node1 <none> <none>
pod-antiaffinity-84d5bf9df4-vk9tc 1/1 Running 0 57s 10.244.3.25 node1 <none> <none>我们可以看到没有被调度到 node2 节点上,因为我们这里使用的是 Pod 反亲和性。
大家可以思考下,如果这里我们将拓扑域更改成 beta.kubernetes.io/os 会怎么样呢?可以自己去测试下看看。
污点与容忍
对于 nodeAffinity 无论是硬策略还是软策略方式,都是调度 Pod 到预期节点上,而污点(Taints)恰好与之相反,如果一个节点标记为 Taints ,除非 Pod 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度 Pod。
比如用户希望把 Master 节点保留给 Kubernetes 系统组件使用,或者把一组具有特殊资源预留给某些 Pod,则污点就很有用了,Pod 不会再被调度到 taint 标记过的节点。
我们使用 kubeadm 搭建的集群默认就给 master 节点添加了一个污点标记,所以我们看到我们平时的 Pod 都没有被调度到 master 上去:
$ kubectl describe node master1
Name: master1
Roles: master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=master1
kubernetes.io/os=linux
node-role.kubernetes.io/master=
......
Taints: node-role.kubernetes.io/master:NoSchedule
Unschedulable: false
......我们可以使用上面的命令查看 master 节点的信息,其中有一条关于 Taints 的信息:node-role.kubernetes.io/master:NoSchedule,就表示master 节点打了一个污点的标记,其中影响的参数是 NoSchedule,表示 Pod 不会被调度到标记为 taints 的节点,除了 NoSchedule 外,还有另外两个选项:
- PreferNoSchedule:NoSchedule 的软策略版本,表示尽量不调度到污点节点上去
- NoExecute:该选项意味着一旦 Taint 生效,如该节点内正在运行的 Pod 没有对应容忍(Tolerate)设置,则会直接被逐出
污点 taint 标记节点的命令如下:
$ kubectl taint nodes node2 test=node2:NoSchedule
node "node2" tainted上面的命名将 node2 节点标记为了污点,影响策略是 NoSchedule,只会影响新的 Pod 调度,如果仍然希望某个 Pod 调度到 taint 节点上,则必须在 Spec 中做出 Toleration 定义,才能调度到该节点,比如现在我们想要将一个 Pod 调度到 master 节点:
# taint-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: taint
labels:
app: taint
spec:
replicas: 3
selector:
matchLabels:
app: taint
template:
metadata:
labels:
app: taint
spec:
containers:
- name: nginx
image: nginx
ports:
- name: http
containerPort: 80
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"由于 master 节点被标记为了污点,所以我们这里要想 Pod 能够调度到改节点去,就需要增加容忍的声明:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"然后创建上面的资源,查看结果:
$ kubectl apply -f taint-demo.yaml
deployment.apps "taint" created
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
......
taint-845d8bb4fb-57mhm 1/1 Running 0 1m 10.244.4.247 node2
taint-845d8bb4fb-bbvmp 1/1 Running 0 1m 10.244.0.33 master1
taint-845d8bb4fb-zb78x 1/1 Running 0 1m 10.244.4.246 node2
......我们可以看到有一个 Pod 副本被调度到了 master 节点,这就是容忍的使用方法。
对于 tolerations 属性的写法,其中的 key、value、effect 与 Node 的 Taint 设置需保持一致, 还有以下几点说明:
- 如果 operator 的值是 Exists,则 value 属性可省略
- 如果 operator 的值是 Equal,则表示其 key 与 value 之间的关系是 equal(等于)
- 如果不指定 operator 属性,则默认值为 Equal
另外,还有两个特殊值:
- 空的 key 如果再配合 Exists 就能匹配所有的 key 与 value,也就是是能容忍所有节点的所有 Taints
- 空的 effect 匹配所有的 effect
最后如果我们要取消节点的污点标记,可以使用下面的命令:
$ kubectl taint nodes node2 test-
node "node2" untainted课后习题
1.不用 DaemonSet,如何使用 Deployment 是否实现同样的功能?
我们知道 DaemonSet 控制器的功能就是在每个节点上运行一个 Pod,如何要使用 Deployment 来实现,首先就要设置副本数量为节点数,比如我们这里加上 master 节点一共3个节点,则要设置3个副本,要在 master 节点上执行自然要添加容忍,那么要如何保证一个节点上只运行一个 Pod 呢?是不是前面的提到的 Pod 反亲和性就可以实现,以自己 Pod 的标签来进行过滤校验即可,新的 Pod 不能运行在一个已经具有该 Pod 的节点上,是不是就是一个节点只能运行一个?模拟的资源清单如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mock-ds-demo
spec:
replicas: 3
selector:
matchLabels:
app: mock-ds-demo
template:
metadata:
labels:
app: mock-ds-demo
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
name: ngpt
affinity:
podAntiAffinity: # pod反亲合性
requiredDuringSchedulingIgnoredDuringExecution: # 硬策略
- labelSelector:
matchExpressions:
- key: app # Pod的标签
operator: In
values: ["mock-ds-demo"]
topologyKey: kubernetes.io/hostname # 以hostname为拓扑域创建上面的资源清单验证:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 84d v1.22.2
node1 Ready <none> 84d v1.22.2
node2 Ready <none> 84d v1.22.2
$ kubectl get pods -l app=mock-ds-demo -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mock-ds-demo-8694759c69-tgqld 1/1 Running 0 30s 10.244.1.198 node1 <none> <none>
mock-ds-demo-8694759c69-wtnwv 1/1 Running 0 30s 10.244.2.29 node2 <none> <none>
mock-ds-demo-8694759c69-zt9pp 1/1 Running 0 30s 10.244.0.135 master1 <none> <none>可以看到我们用 Deployment 部署的服务在每个节点上都运行了一个 Pod,实现的效果和 DaemonSet 是一致的。
2.同样的如果想在每个节点(或指定的一些节点)上运行2个(或多个)Pod 副本,如何实现?
DaemonSet 是在每个节点上运行1个 Pod 副本,显然我们去创建2个(或多个)DaemonSet 即可实现该目标,但是这不是一个好的接近方案,而 PodAntiAffinity 只能将一个 Pod 调度到某个拓扑域中去,所以都不能很好的来解决这个问题。
要实现这种更细粒度的控制,我们可以通过设置拓扑分布约束来进行调度,设置拓扑分布约束来将 Pod 分布到不同的拓扑域下,从而实现高可用性或节省成本,具体实现方式请看下文。