DaemonSet 控制器
作者: ryan 发布于: 8/17/2025 更新于: 8/17/2025 字数: 0 字 阅读: 0 分钟
通过该控制器的名称我们可以看出它的用法:Daemon,就是用来部署守护进程的,DaemonSet用于在每个 Kubernetes 节点中将守护进程的副本作为后台进程运行,说白了就是在每个节点部署一个 Pod 副本,当节点加入到 Kubernetes 集群中,Pod 会被调度到该节点上运行,当节点从集群只能够被移除后,该节点上的这个 Pod 也会被移除,当然,如果我们删除 DaemonSet,所有和这个对象相关的 Pods 都会被删除。
那么在哪种情况下我们会需要用到这种业务场景呢?其实这种场景还是比较普通的,比如:
- 集群存储守护程序,如
glusterd、ceph要部署在每个节点上以提供持久性存储; - 节点监控守护进程,如
Prometheus监控集群,可以在每个节点上运行一个 node-exporter 进程来收集监控节点的信息; - 日志收集守护程序,如
fluentd或logstash,在每个节点上运行以收集容器的日志 - 节点网络插件,比如
flannel、calico,在每个节点上运行为 Pod 提供网络服务。
这里需要特别说明的一个就是关于 DaemonSet 运行的 Pod 的调度问题,正常情况下,Pod 运行在哪个节点上是由 Kubernetes 的调度器策略来决定的,然而,由 DaemonSet 控制器创建的 Pod 实际上提前已经确定了在哪个节点上了(Pod 创建时指定了.spec.nodeName),所以:
- DaemonSet 并不关心一个节点的
unshedulable字段,这个我们会在后面的调度章节和大家讲解的。 - DaemonSet 可以创建 Pod,即使调度器还没有启动。
下面我们直接使用一个示例来演示下,在每个节点上部署一个 Nginx Pod:
# nginx-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nginx-ds
namespace: default
spec:
selector:
matchLabels:
k8s-app: nginx
template:
metadata:
labels:
k8s-app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- name: http
containerPort: 80直接创建即可:
$ kubectl apply -f nginx-ds.yaml
daemonset.apps/nginx-ds created创建完成后,我们查看 Pod 的状态:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 18d v1.22.2
node1 Ready <none> 18d v1.22.2
node2 Ready <none> 18d v1.22.2
$ kubectl get pods -l k8s-app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-ds-5b2m7 1/1 Running 0 15s 10.244.2.165 node2 <none> <none>
nginx-ds-jfr89 1/1 Running 0 15s 10.244.1.170 node1 <none> <none>我们观察可以发现除了 master1 节点之外的 2 个节点上都有一个相应的 Pod 运行,因为 master1 节点上默认被打上了污点,所以默认情况下不能调度普通的 Pod 上去,后面讲解调度器的时候会和大家学习如何调度上去。
基本上我们可以用下图来描述 DaemonSet 的拓扑图:
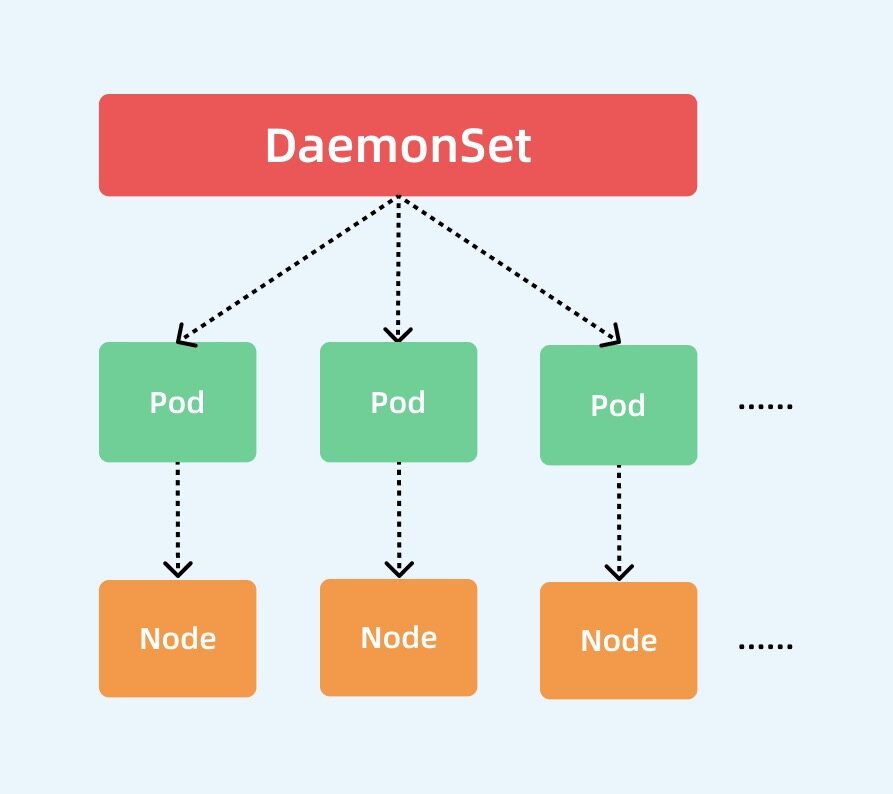
集群中的 Pod 和 Node 是一一对应的,而 DaemonSet 会管理全部机器上的 Pod 副本,负责对它们进行更新和删除。
那么,DaemonSet 控制器是如何保证每个 Node 上有且只有一个被管理的 Pod 呢?
- 首先控制器从 Etcd 获取到所有的 Node 列表,然后遍历所有的 Node。
- 根据资源对象定义是否有调度相关的配置,然后分别检查 Node 是否符合要求。
- 在可运行 Pod 的节点上检查是否已有对应的 Pod,如果没有,则在这个 Node 上创建该 Pod;如果有,并且数量大于 1,那就把多余的 Pod 从这个节点上删除;如果有且只有一个 Pod,那就说明是正常情况。
实际上当我们学习了资源调度后,我们也可以自己用 Deployment 来实现 DaemonSet 的效果,这里我们明白 DaemonSet 如何使用的即可,当然该资源对象也有对应的更新策略,有 OnDelete 和 RollingUpdate 两种方式,默认是滚动更新。
Job 与 CronJob
作者: ryan 发布于: 8/17/2025 更新于: 8/17/2025 字数: 0 字 阅读: 0 分钟
接下来给大家介绍另外一类资源对象:Job,我们在日常的工作中经常都会遇到一些需要进行批量数据处理和分析的需求,当然也会有按时间来进行调度的工作,在我们的 Kubernetes 集群中为我们提供了 Job 和 CronJob 两种资源对象来应对我们的这种需求。
Job 负责处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
而CronJob 则就是在 Job 上加上了时间调度。
Job
我们用 Job 这个资源对象来创建一个任务,我们定义一个 Job 来执行一个倒计时的任务,对应的资源清单如下所示:
# job-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
template:
spec:
restartPolicy: Never
containers:
- name: counter
image: busybox
command:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"我们可以看到 Job 中也是一个 Pod 模板,和之前的 Deployment、StatefulSet 之类的是一致的,只是 Pod 中的容器要求是一个任务,而不是一个常驻前台的进程了,因为需要退出,另外值得注意的是 Job 的 RestartPolicy 仅支持 Never 和 OnFailure 两种,不支持 Always,我们知道 Job 就相当于来执行一个批处理任务,执行完就结束了,如果支持 Always 的话是不是就陷入了死循环了?
直接创建这个 Job 对象:
$ kubectl apply -f job-demo.yaml
job.batch/job-demo created
$ kubectl get job
NAME COMPLETIONS DURATION AGE
job-demo 1/1 19s 42s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
job-demo--1-p9s5r 0/1 Completed 0 52sJob 对象创建成功后,我们可以查看下对象的详细描述信息:
$ kubectl describe job job-demo
Name: job-demo
Namespace: default
Selector: controller-uid=10618fc6-5610-41c6-bdeb-531167716179
Labels: controller-uid=10618fc6-5610-41c6-bdeb-531167716179
job-name=job-demo
Annotations: <none>
Parallelism: 1
Completions: 1
Completion Mode: NonIndexed
Start Time: Sat, 13 Nov 2021 18:34:17 +0800
Completed At: Sat, 13 Nov 2021 18:34:36 +0800
Duration: 19s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=10618fc6-5610-41c6-bdeb-531167716179
job-name=job-demo
Containers:
counter:
Image: busybox
Port: <none>
Host Port: <none>
Command:
bin/sh
-c
for i in 9 8 7 6 5 4 3 2 1; do echo $i; done
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 73s job-controller Created pod: job-demo--1-p9s5r
Normal Completed 54s job-controller Job completed可以看到,Job 对象在创建后,它的 Pod 模板,被自动加上了一个 controller-uid=< 一个随机字符串 > 这样的 Label 标签,而这个 Job 对象本身,则被自动加上了这个 Label 对应的 Selector,从而保证了 Job 与它所管理的 Pod 之间的匹配关系。
而 Job 控制器之所以要使用这种携带了 UID 的 Label,就是为了避免不同 Job 对象所管理的 Pod 发生重合。
我们可以看到很快 Pod 变成了 Completed 状态,这是因为容器的任务执行完成正常退出了,我们可以查看对应的日志:
$ kubectl logs job-demo--1-p9s5r
9
8
7
6
5
4
3
2
1
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
job-demo--1-p9s5r 0/1 Completed 0 11m上面我们这里的 Job 任务对应的 Pod 在运行结束后,会变成 Completed 状态,但是如果执行任务的 Pod 因为某种原因一直没有结束怎么办呢?同样我们可以在 Job 对象中通过设置字段 spec.activeDeadlineSeconds 来限制任务运行的最长时间,比如:
spec:
activeDeadlineSeconds: 100那么当我们的任务 Pod 运行超过了 100s 后,这个 Job 的所有 Pod 都会被终止,并且, Pod 的终止原因会变成 DeadlineExceeded。
如果的任务执行失败了,会怎么处理呢,这个和定义的 restartPolicy 有关系,比如定义如下所示的 Job 任务,定义 restartPolicy: Never 的重启策略:
# job-failed-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-failed-demo
spec:
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo123", "test failed job!"]
restartPolicy: Never直接创建上面的资源对象:
$ kubectl apply -f job-failed-demo.yaml
job.batch/job-failed-demo created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
job-failed-demo--1-87wvj 0/1 StartError 0 4m40s
job-failed-demo--1-bl7jm 0/1 StartError 0 5m7s
job-failed-demo--1-dcmph 0/1 StartError 0 3m
job-failed-demo--1-hb24j 0/1 StartError 0 20s
job-failed-demo--1-n7h24 0/1 StartError 0 4m20s
job-failed-demo--1-q7vxq 0/1 StartError 0 5m24s可以看到当我们设置成 Never 重启策略的时候,Job 任务执行失败后会不断创建新的 Pod,但是不会一直创建下去,会根据 spec.backoffLimit 参数进行限制,默认为6,通过该字段可以定义重建 Pod 的次数,另外需要注意的是 Job 控制器重新创建 Pod 的间隔是呈指数增加的,即下一次重新创建 Pod 的动作会分别发生在 10s、20s、40s… 后。
但是如果我们设置的 restartPolicy: OnFailure 重启策略,则当 Job 任务执行失败后不会创建新的 Pod 出来,只会不断重启 Pod。
除此之外,我们还可以通过设置 spec.parallelism 参数来进行并行控制,该参数定义了一个 Job 在任意时间最多可以有多少个 Pod 同时运行。
spec.completions 参数可以定义 Job 至少要完成的 Pod 数目。
如下所示创建一个新的 Job 任务,设置允许并行数为2,至少要完成的 Pod 数为8:
# job-para-demo.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: job-para-test
spec:
parallelism: 2
completions: 8
template:
spec:
containers:
- name: test-job
image: busybox
command: ["echo", "test paralle job!"]
restartPolicy: Never创建完成后查看任务状态:
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
job-para-test--1-rwxm8 0/1 ContainerCreating 0 6s
job-para-test--1-vgtxf 0/1 ContainerCreating 0 2s
$ kubectl get job
NAME COMPLETIONS DURATION AGE
job-para-test 0/8 29s 29s
$ kubectl get job
NAME COMPLETIONS DURATION AGE
job-para-test 8/8 111s 2m34s
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
job-para-test--1-7nk2x 0/1 Completed 0 76s
job-para-test--1-dcdvp 0/1 Completed 0 2m2s
job-para-test--1-k9sgw 0/1 Completed 0 2m36s
job-para-test--1-rwkkb 0/1 Completed 0 2m17s
job-para-test--1-rwxm8 0/1 Completed 0 2m36s
job-para-test--1-tqlzd 0/1 Completed 0 106s
job-para-test--1-vgtxf 0/1 Completed 0 2m32s
job-para-test--1-vxj6b 0/1 Completed 0 91s可以看到一次可以有2个 Pod 同时运行,需要8个 Pod 执行成功,如果不是8个成功,那么会根据 restartPolicy 的策略进行处理,可以认为是一种检查机制。
CronJob
CronJob 其实就是在 Job 的基础上加上了时间调度,我们可以在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。
这个实际上和我们 Linux 中的 crontab 就非常类似了。
一个 CronJob 对象其实就对应中 crontab 文件中的一行,它根据配置的时间格式周期性地运行一个 Job,格式和 crontab 也是一样的。
crontab 的格式
crontab 的格式为:分 时 日 月 星期 要运行的命令
- 第1列分钟 0~59
- 第2列小时 0~23
- 第3列日 1~31
- 第4列月 1~12
- 第5列星期 0~7(0和7表示星期天)
- 第6列要运行的命令
现在,我们用 CronJob 来管理我们上面的 Job 任务,定义如下所示的资源清单:
# cronjob-demo.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-demo
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: hello
image: busybox
args:
- "bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"这里的 Kind 变成了 CronJob 了,要注意的是 .spec.schedule 字段是必须填写的,用来指定任务运行的周期,格式就和 crontab 一样,另外一个字段是 .spec.jobTemplate, 用来指定需要运行的任务,格式当然和 Job 是一致的。
还有一些值得我们关注的字段 .spec.successfulJobsHistoryLimit(默认为3) 和 .spec.failedJobsHistoryLimit(默认为1),表示历史限制,是可选的字段,指定可以保留多少完成和失败的 Job。
然而,当运行一个 CronJob 时,Job 可以很快就堆积很多,所以一般推荐设置这两个字段的值,如果设置限制的值为 0,那么相关类型的 Job 完成后将不会被保留。
我们直接新建上面的资源对象:
$ kubectl apply -f cronjob-demo.yaml
cronjob "cronjob-demo" created然后可以查看对应的 Cronjob 资源对象:
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-demo */1 * * * * False 0 28s 36s稍微等一会儿查看可以发现多了几个 Job 资源对象,这个就是因为上面我们设置的 CronJob 资源对象,每1分钟执行一个新的 Job:
$ kubectl get job
NAME COMPLETIONS DURATION AGE
cronjob-demo-27280016 1/1 17s 118s
cronjob-demo-27280017 1/1 16s 58s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cronjob-demo-27280016--1-kvkt4 0/1 Completed 0 2m9s
cronjob-demo-27280017--1-pkwdb 0/1 Completed 0 69s
cronjob-demo-27280018--1-q9n7w 0/1 ContainerCreating 0 9s这个就是 CronJob 的基本用法,一旦不再需要 CronJob,我们可以使用 kubectl 命令删除它:
$ kubectl delete cronjob cronjob-demo
cronjob "cronjob-demo" deleted不过需要注意的是这将会终止正在创建的 Job,但是运行中的 Job 将不会被终止,不会删除 Job 或 它们的 Pod。
思考:那如果我们想要在每个节点上去执行一个 Job 或者 Cronjob 又该怎么来实现呢?