使用Kafka优化EFK
作者: Ryan 发布于: 2/29/2024 更新于: 8/16/2025 字数: 0 字 阅读: 0 分钟
安装 Kafka
对于大规模集群来说,日志数据量是非常巨大的,如果直接通过 Fluentd 将日志打入 Elasticsearch,对 ES 来说压力是非常巨大的,我们可以在中间加一层消息中间件来缓解 ES 的压力,一般情况下我们会使用 Kafka,然后可以直接使用 kafka-connect-elasticsearch 这样的工具将数据直接打入 ES,也可以在加一层 Logstash 去消费 Kafka 的数据,然后通过 Logstash 把数据存入 ES,这里我们来使用 Logstash 这种模式来对日志收集进行优化。
首先在 Kubernetes 集群中安装 Kafka,同样这里使用 Helm 进行安装:
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm repo update拉取 kafka-Chart 包
首先使用 helm pull 拉取 Chart 并解压:
$ helm pull bitnami/kafka --untar --version 17.2.3
$ cd kafka配置 values
这里面我们指定使用一个 StorageClass 来提供持久化存储,在 Chart 目录下面创建用于安装的 values 文件:
# values-prod.yaml
## @section Persistence parameters
persistence:
enabled: true
storageClass: 'rook-ceph-block-test1'
accessModes:
- ReadWriteOnce
size: 8Gi
mountPath: /bitnami/kafka
# 配置zk volumes
zookeeper:
enabled: true
persistence:
enabled: true
storageClass: 'rook-ceph-block-test1'
accessModes:
- ReadWriteOnce
size: 8Giimage:
registry: registry.cn-beijing.aliyuncs.com/xxk8s
repository: kafka
tag: 3.2.0-debian-10-r4
pullPolicy: IfNotPresent
persistence:
enabled: true
existingClaim: ""
storageClass: "rook-ceph-block-test1"
accessModes:
- ReadWriteOnce
size: 50Gi
annotations: {}
selector: {}
mountPath: /bitnami/kafka
zookeeper:
enabled: true
replicaCount: 1
persistence:
enabled: true
storageClass: "rook-ceph-block-test1"
accessModes:
- ReadWriteOnce
size: 50Givim charts/zookeeper/values.yaml
image:
registry: registry.cn-beijing.aliyuncs.com/xxk8s
repository: zookeeper
tag: 3.8.0-debian-10-r64
pullPolicy: IfNotPresent直接使用上面的 values 文件安装 kafka:
$ helm upgrade --install kafka -f values-prod.yaml --namespace logging .
root@master01:/k8s-logging/kafka# helm upgrade --install kafka -f values-prod.yaml --namespace logging .
Release "kafka" does not exist. Installing it now.
NAME: kafka
LAST DEPLOYED: Sat Aug 31 23:20:02 2024
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 17.2.3
APP VERSION: 3.2.0
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.logging.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-0.kafka-headless.logging.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image registry.cn-beijing.aliyuncs.com/xxk8s//kafka:3.2.0-debian-10-r4 --namespace logging --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace logging -- bash
PRODUCER:
kafka-console-producer.sh \
--broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.logging.svc.cluster.local:9092 \
--topic test \
--from-beginning查看运行状态
安装完成后我们可以使用上面的提示来检查 Kafka 是否正常运行:
root@master01:/k8s-logging/kafka# kubectl get pods -n logging -l app.kubernetes.io/instance=kafka
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 3m10s
kafka-zookeeper-0 1/1 Running 0 65s测试消息队列
用下面的命令创建一个 Kafka 的测试客户端 Pod:
root@master01:/k8s-logging# kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test
>hello kafka on k8s
[2024-09-01 09:43:10,839] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 4 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
[2024-09-01 09:43:10,948] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 5 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
[2024-09-01 09:43:11,055] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 6 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
[2024-09-01 09:43:11,162] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 7 : {test=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
>然后启动一个终端进入容器内部生产消息:
# 生产者
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-producer.sh --broker-list kafka-0.kafka-headless.logging.svc.cluster.local:9092 --topic test
>hello kafka on k8s
>启动另外一个终端进入容器内部消费消息:
# 消费者
root@master01:~# kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic test --from-beginning
hello kafka on k8s如果在消费端看到了生产的消息数据证明我们的 Kafka 已经运行成功了。
在 Fluentd 配置 Kafka
现在有了 Kafka,我们就可以将 Fluentd 的日志数据输出到 Kafka 了,只需要将 Fluentd 配置中的 <match> 更改为使用 Kafka 插件即可,但是在 Fluentd 中输出到 Kafka,需要使用到 fluent-plugin-kafka 插件,所以需要我们自定义下 Docker 镜像,最简单的做法就是在上面 Fluentd 镜像的基础上新增 kafka 插件即可,Dockerfile 文件如下所示:
FROM registry.cn-beijing.aliyuncs.com/xxk8s/fluentd:v3.4.0
RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" > Gemfile && gem install bundler
RUN gem install fluent-plugin-kafka -v 0.17.5 --no-document构建镜像
root@harbor01[17:54:26]/dockerfile/fluentd #:vim dockerfile
root@harbor01[17:56:38]/dockerfile/fluentd #:docker build -t registry.cn-beijing.aliyuncs.com/xxk8s/fluentd-kafka:v0.17.5 .
DEPRECATED: The legacy builder is deprecated and will be removed in a future release.
Install the buildx component to build images with BuildKit:
https://docs.docker.com/go/buildx/
Sending build context to Docker daemon 2.048kB
Step 1/3 : FROM registry.cn-beijing.aliyuncs.com/xxk8s/fluentd:v3.4.0
---> 48fa67e45697
Step 2/3 : RUN echo "source 'https://mirrors.tuna.tsinghua.edu.cn/rubygems/'" > Gemfile && gem install bundler -v 2.4.22
---> Running in 272e428c22dc
Successfully installed bundler-2.4.22
1 gem installed
Removing intermediate container 272e428c22dc
---> 9a32b47ecf5b
Step 3/3 : RUN gem install fluent-plugin-kafka -v 0.17.5 --no-document
---> Running in 378648ec7966
Building native extensions. This could take a while...
Successfully installed digest-crc-0.6.5
Successfully installed ruby-kafka-1.5.0
Successfully installed ltsv-0.1.2
Successfully installed fluent-plugin-kafka-0.17.5
4 gems installed
Removing intermediate container 378648ec7966
---> 75f10f295541
Successfully built 75f10f295541
Successfully tagged registry.cn-beijing.aliyuncs.com/xxk8s/fluentd-kafka:v0.17.5更改Fluentd Configmap
使用上面的 Dockerfile 文件构建一个 Docker 镜像即可,我这里构建过后的镜像名为 registry.cn-beijing.aliyuncs.com/xxk8s/fluentd-kafka:v0.17.5。
接下来替换 Fluentd 的 Configmap 对象中的 <match> 部分,如下所示:
# fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-conf
namespace: logging
data:
......
output.conf: |-
<match **>
@id kafka
@type kafka2
@log_level info
# list of seed brokers
brokers kafka-0.kafka-headless.logging.svc.cluster.local:9092
use_event_time true
# topic settings
topic_key k8slog
default_topic messages # 注意,kafka中消费使用的是这个topic
# buffer settings
<buffer k8slog>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# producer settings
required_acks -1
compression_codec gzip
</match>替换Fluentd 镜像
root@master01:/k8s-logging# kubectl apply -f fluentd-configmap.yaml -n logging
configmap/fluentd-conf configured替换运行的 Fluentd 镜像:
# fluentd-daemonset.yaml
image: registry.cn-beijing.aliyuncs.com/xxk8s/fluentd-kafka:v0.17.5应用配置
直接更新 Fluentd 的 Configmap 与 DaemonSet 资源对象即可:
root@master01:/k8s-logging# kubectl apply -f fluentd-daemonset.yaml -n logging
serviceaccount/fluentd-es unchanged
clusterrole.rbac.authorization.k8s.io/fluentd-es unchanged
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es configured
daemonset.apps/fluentd configured测试日志数据
更新成功后我们可以使用上面的测试 Kafka 客户端来验证是否有日志数据:
$ kubectl exec --tty -i kafka-client --namespace logging -- bash
I have no name!@kafka-client:/$ kafka-console-consumer.sh --bootstrap-server kafka.logging.svc.cluster.local:9092 --topic messages --from-beginning
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"logging","pod_name":"counter-log","container_image":"registry.cn-beijing.aliyuncs.com/xxk8s/busybox:1.36.1","pod_ip":"10.244.2.68","host":"node01","labels":{"logging":"true"},"namespace_labels":{"kubernetes_io/metadata_name":"logging"}},"message":"87373: Sun Sep 1 10:12:04 UTC 2024"}
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"logging","pod_name":"counter-log","container_image":"registry.cn-beijing.aliyuncs.com/xxk8s/busybox:1.36.1","pod_ip":"10.244.2.68","host":"node01","labels":{"logging":"true"},"namespace_labels":{"kubernetes_io/metadata_name":"logging"}},"message":"87374: Sun Sep 1 10:12:05 UTC 2024"}
{"stream":"stdout","docker":{},"kubernetes":{"container_name":"count","namespace_name":"logging","pod_name":"counter-log","container_image":"registry.cn-beijing.aliyuncs.com/xxk8s/busybox:1.36.1","pod_ip":"10.244.2.68","host":"node01","labels":{"logging":"true"},"namespace_labels":{"kubernetes_io/metadata_name":"logging"}},"message":"87375: Sun Sep 1 10:12:06 UTC 2024"}
...安装 Logstash
虽然数据从 Kafka 到 Elasticsearch 的方式多种多样,比如可以使用 Kafka Connect Elasticsearch Connector 来实现,我们这里还是采用更加流行的 Logstash`` 方案,上面我们已经将日志从 Fluentd 采集输出到 Kafka 中去了,接下来我们使用 Logstash 来连接 Kafka 与 Elasticsearch 间的日志数据。<br />首先使用 helm pull` 拉取 Chart 并解压:
$ helm pull elastic/logstash --untar --version 7.17.3
$ cd logstash同样在 Chart 根目录下面创建用于安装的 Values 文件,如下所示:
# values-prod.yaml
fullnameOverride: logstash
image: "registry.cn-beijing.aliyuncs.com/xxk8s/logstash"
imageTag: "7.17.3"
imagePullPolicy: "IfNotPresent"
imagePullSecrets: []
persistence:
enabled: true
logstashConfig:
logstash.yml: |
http.host: 0.0.0.0
# 如果启用了xpack,需要做如下配置
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.hosts: ["http://elasticsearch-client:9200"]
xpack.monitoring.elasticsearch.username: "elastic"
xpack.monitoring.elasticsearch.password: "LUFehLTd0WanaCcfmYYk"
# 要注意下格式
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 过滤配置(比如可以删除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "LUFehLTd0WanaCcfmYYk" index => "logstash-k8s-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
volumeClaimTemplate:
accessModes: ['ReadWriteOnce']
storageClassName: rook-ceph-block-test1
resources:
requests:
storage: 5Gi其中最重要的就是通过 logstashPipeline 配置 logstash 数据流的处理配置,通过 input 指定日志源 kafka 的配置,通过 output 输出到 Elasticsearch,同样直接使用上面的 Values 文件安装 logstash 即可:
root@master01:/k8s-logging/logstash# helm upgrade --install logstash -f values-prod.yaml --namespace logging .
Release "logstash" does not exist. Installing it now.
NAME: logstash
LAST DEPLOYED: Sun Sep 1 22:53:02 2024
NAMESPACE: logging
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=logstash -w安装启动完成后可以查看 logstash 的日志:
root@master01:/k8s-logging/logstash# kubectl get pods --namespace=logging -l app=logstash
NAME READY STATUS RESTARTS AGE
logstash-0 1/1 Running 0 9m34s
$ kubectl logs -f logstash-0 -n logging
......
"stream" => "stdout",
"@timestamp" => 2024-09-01T14:55:48.155Z,
"kubernetes" => {
"pod_name" => "counter-log",
"container_name" => "count",
"pod_ip" => "10.244.2.68",
"namespace_labels" => {
"kubernetes_io/metadata_name" => "logging"
},
"container_image" => "registry.cn-beijing.aliyuncs.com/xxk8s/busybox:1.36.1",
"namespace_name" => "logging",
"host" => "node01",
"labels" => {
"logging" => "true"
}
},
"@version" => "1",
"message" => "104362: Sun Sep 1 14:55:46 UTC 2024",
"docker" => {}
}
{
"stream" => "stdout",
"@timestamp" => 2024-09-01T14:55:48.156Z,
"kubernetes" => {
"pod_name" => "counter-log",
"container_name" => "count",
"pod_ip" => "10.244.2.68",
"namespace_labels" => {
"kubernetes_io/metadata_name" => "logging"
},
"container_image" => "registry.cn-beijing.aliyuncs.com/xxk8s/busybox:1.36.1",
"namespace_name" => "logging",
"host" => "node01",
"labels" => {
"logging" => "true"
}
},
"@version" => "1",
"message" => "104363: Sun Sep 1 14:55:47 UTC 2024",
"docker" => {}
}由于我们启用了 debug 日志调试,所以我们可以在 logstash 的日志中看到我们采集的日志消息,到这里证明我们的日志数据就获取成功了。
现在我们可以登录到 Kibana 可以看到有如下所示的索引数据了: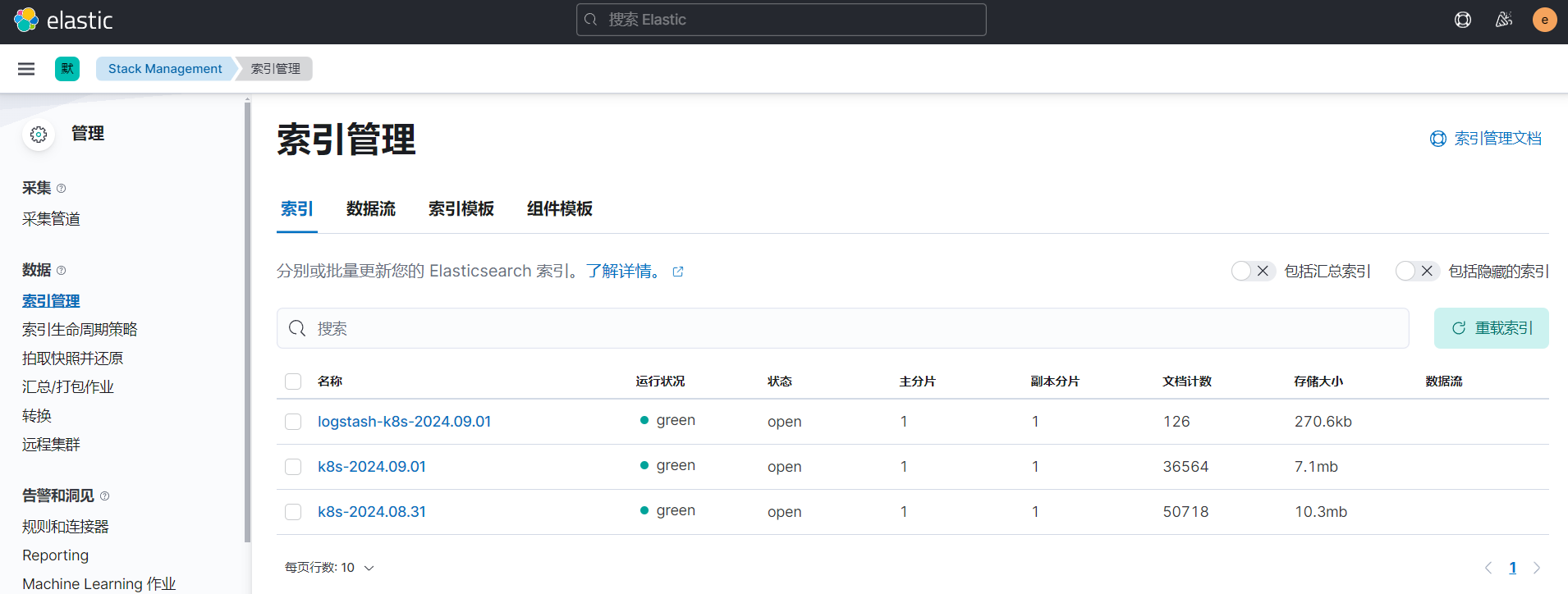
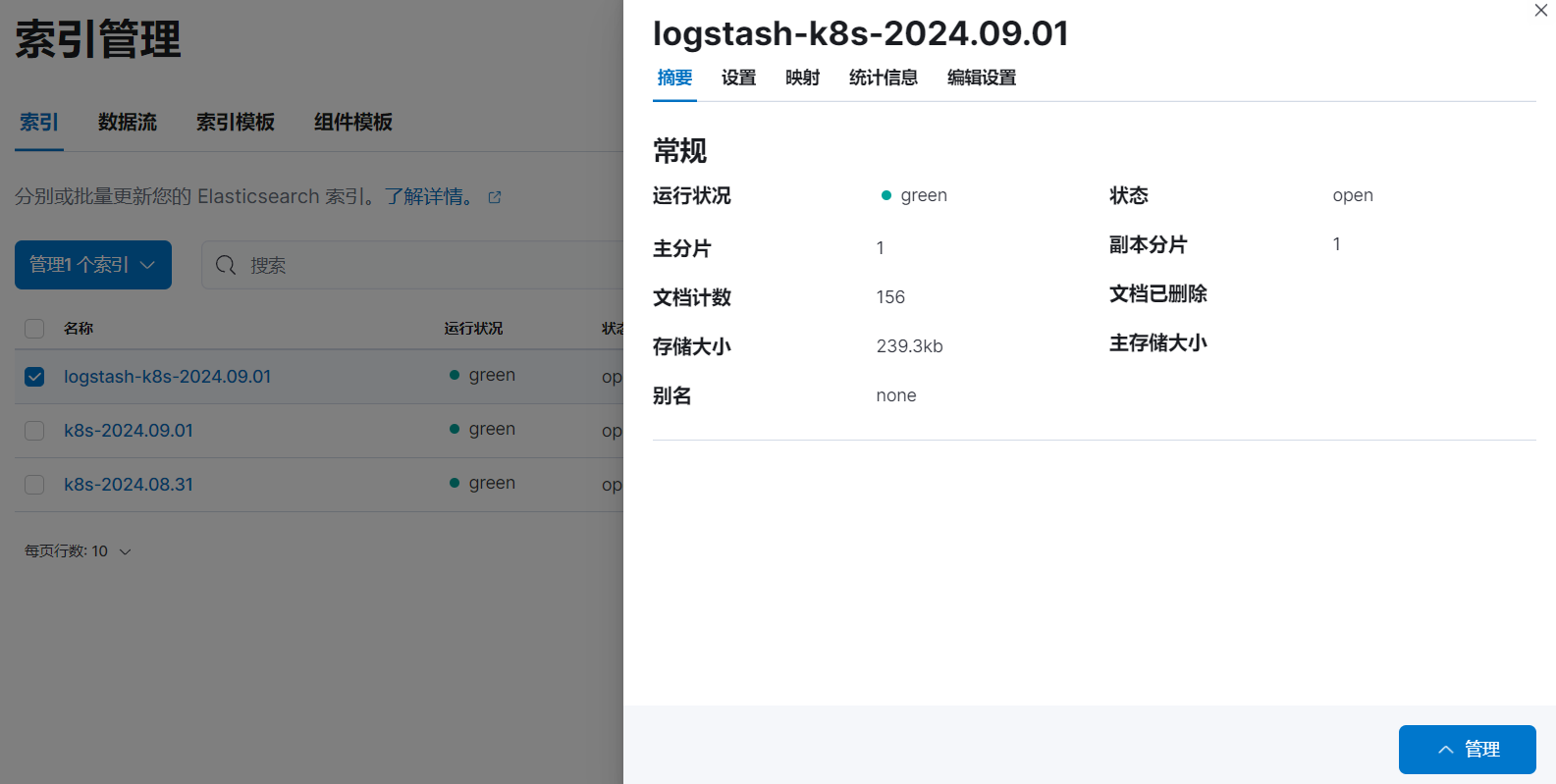
然后同样创建索引模式,匹配上面的索引即可: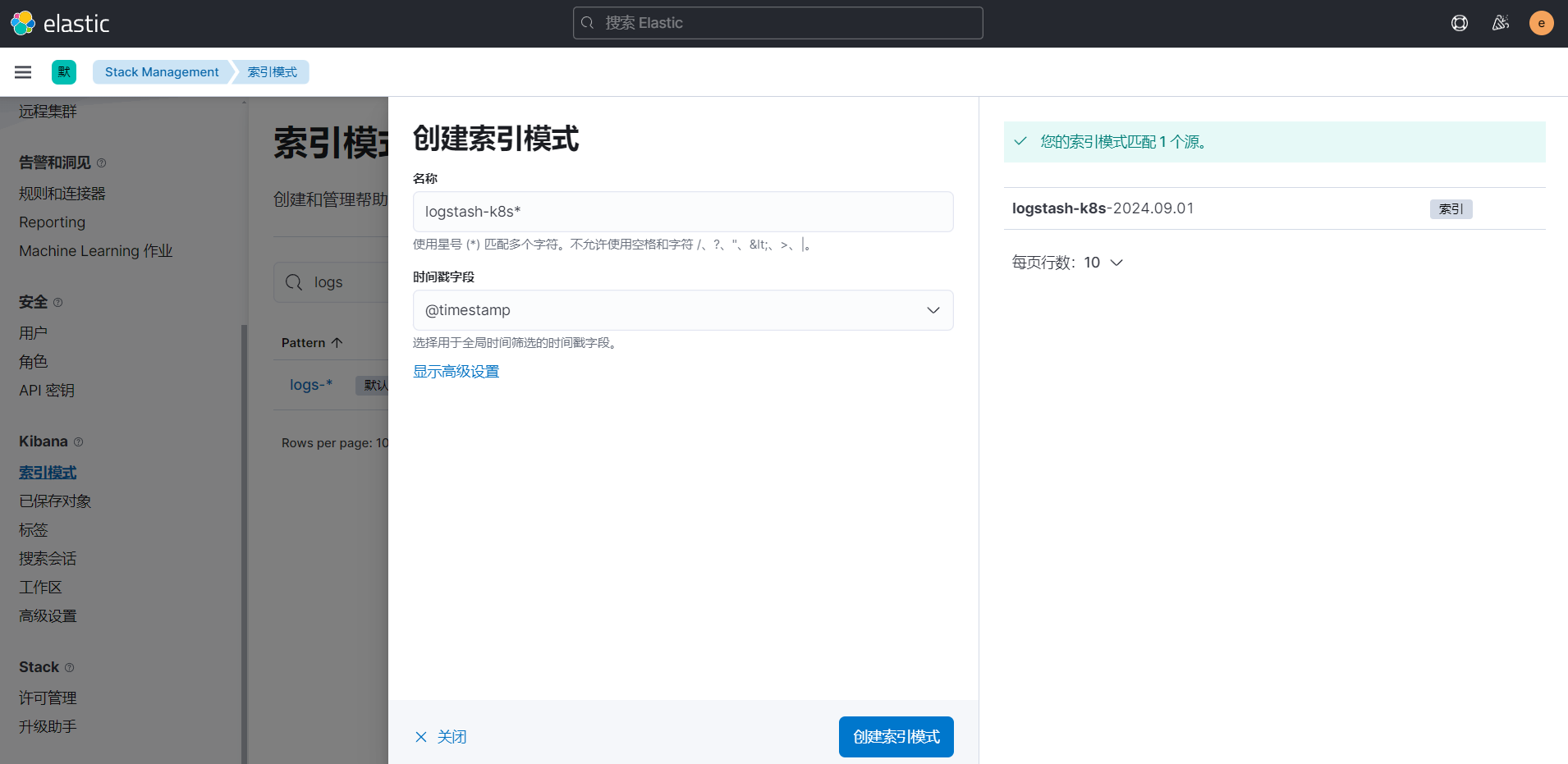
创建完成后就可以前往发现页面过滤日志数据了: 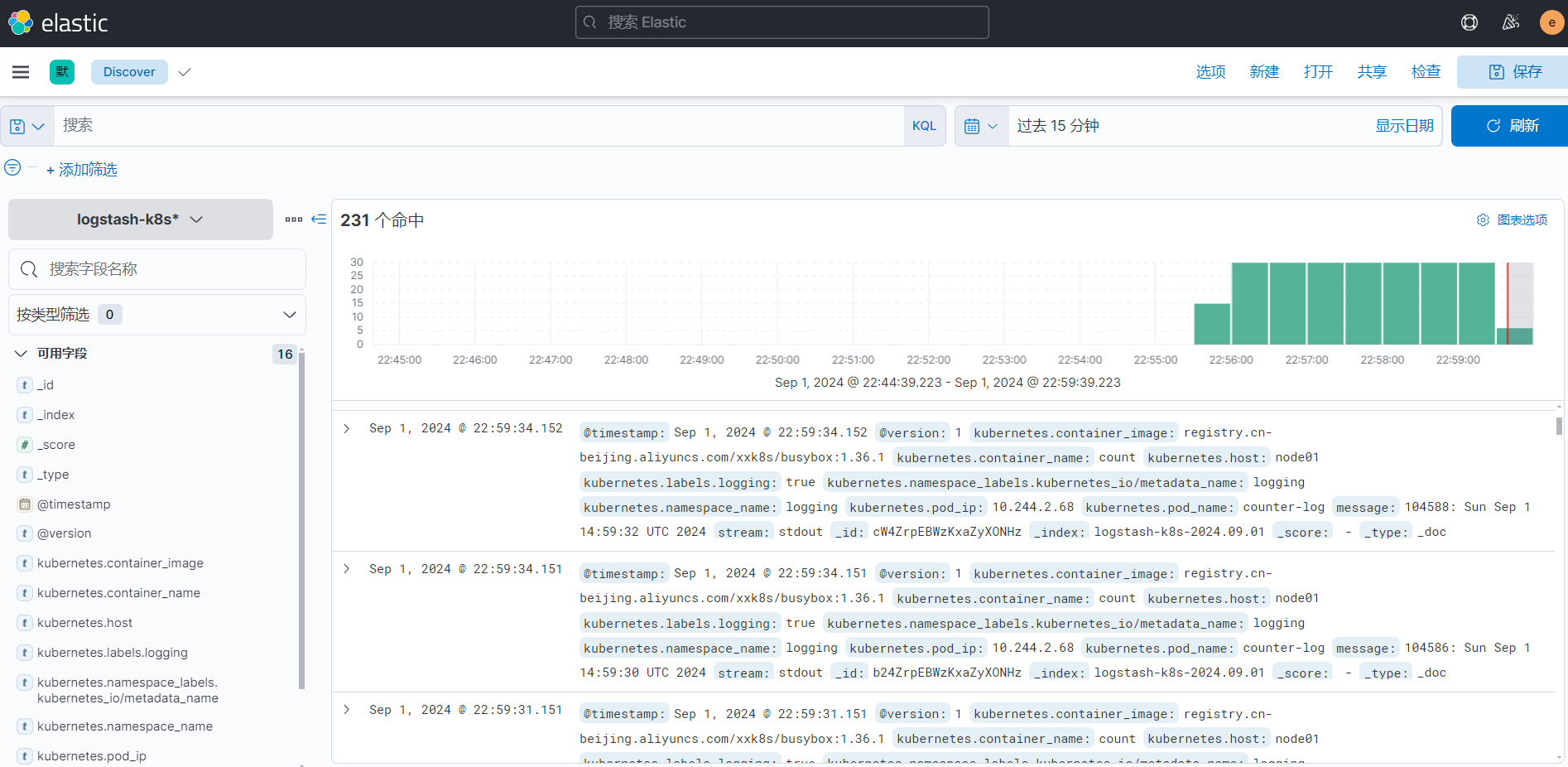
到这里我们就实现了一个使用 Fluentd+Kafka+Logstash+Elasticsearch+Kibana 的 Kubernetes 日志收集工具栈,这里我们完整的 Pod 信息如下所示:
root@master01:/k8s-logging/logstash# kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
counter 3/3 Running 0 11d
counter-log 1/1 Running 0 29h
elasticsearch-client-0 1/1 Running 0 29h
elasticsearch-client-1 1/1 Running 0 29h
elasticsearch-data-0 1/1 Running 0 29h
elasticsearch-data-1 1/1 Running 0 29h
elasticsearch-data-2 1/1 Running 0 29h
elasticsearch-master-0 1/1 Running 0 29h
elasticsearch-master-1 1/1 Running 0 29h
elasticsearch-master-2 1/1 Running 0 29h
fluentd-57fgr 1/1 Running 0 4h49m
fluentd-ft7zf 1/1 Running 0 4h49m
fluentd-hd2ph 1/1 Running 0 4h49m
kafka-0 1/1 Running 0 23h
kafka-client 1/1 Running 0 5h18m
kafka-zookeeper-0 1/1 Running 0 23h
kibana-kibana-67bc7c764b-hs2hc 1/1 Running 0 29h
logstash-0 1/1 Running 0 7m10s自定义索引名称
当然在实际的工作项目中还需要我们根据实际的业务场景来进行参数性能调优以及高可用等设置,以达到系统的最优性能。
上面我们在配置 logstash 的时候是将日志输出到 "logstash-k8s-%{+YYYY.MM.dd}" 这个索引模式的,可能有的场景下只通过日期去区分索引不是很合理,那么我们可以根据自己的需求去修改索引名称,比如可以根据我们的服务名称来进行区分,那么这个服务名称可以怎么来定义呢?
可以是 Pod 的名称或者通过 label 标签去指定,比如我们这里去做一个规范,要求需要收集日志的 Pod 除了需要添加 logging: true 这个标签之外,还需要添加一个 logIndex: <索引名> 的标签。
比如重新更新我们测试的 counter 应用:
apiVersion: v1
kind: Pod
metadata:
name: counter
labels:
logging: 'true' # 一定要具有该标签才会被采集
logIndex: 'test' # 指定索引名称
spec:
containers:
- name: count
image: busybox
args:
[
/bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]然后重新更新 logstash 的配置,修改 values 配置:
# ......
logstashPipeline:
logstash.conf: |
input { kafka { bootstrap_servers => "kafka-0.kafka-headless.logging.svc.cluster.local:9092" codec => json consumer_threads => 3 topics => ["messages"] } }
filter {} # 过滤配置(比如可以删除key、添加geoip等等)
output { elasticsearch { hosts => [ "elasticsearch-client:9200" ] user => "elastic" password => "LUFehLTd0WanaCcfmYYk" index => "k8s-%{[kubernetes][labels][logIndex]}-%{+YYYY.MM.dd}" } stdout { codec => rubydebug } }
# ......root@master01:/k8s-logging/logstash# helm upgrade --install logstash -f values-prod.yaml --namespace logging .
Release "logstash" has been upgraded. Happy Helming!
NAME: logstash
LAST DEPLOYED: Mon Sep 2 09:41:19 2024
NAMESPACE: logging
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=logging -l app=logstash -w{
"docker" => {},
"stream" => "stdout",
"@version" => "1",
"kubernetes" => {
"labels" => {
"logging" => "true",
"logIndex" => "test"
},
"pod_ip" => "10.244.2.68",
"host" => "node01",
"namespace_name" => "logging",
"namespace_labels" => {
"kubernetes_io/metadata_name" => "logging"
},
"container_image" => "registry.cn-beijing.aliyuncs.com/xxk8s/busybox:1.36.1",
"pod_name" => "counter-log",
"container_name" => "count"
},
"message" => "143838: Mon Sep 2 01:54:58 UTC 2024",
"@timestamp" => 2024-09-02T01:55:00.641Z
}
{访问 bibana http://10.1.0.16:30601
使用上面的 values 值更新 logstash,正常更新后上面的 counter 这个 Pod 日志会输出到一个名为 k8s-test-2022.06.09 的索引去。
import ZoomImage from '@site/src/components/ZoomImage';
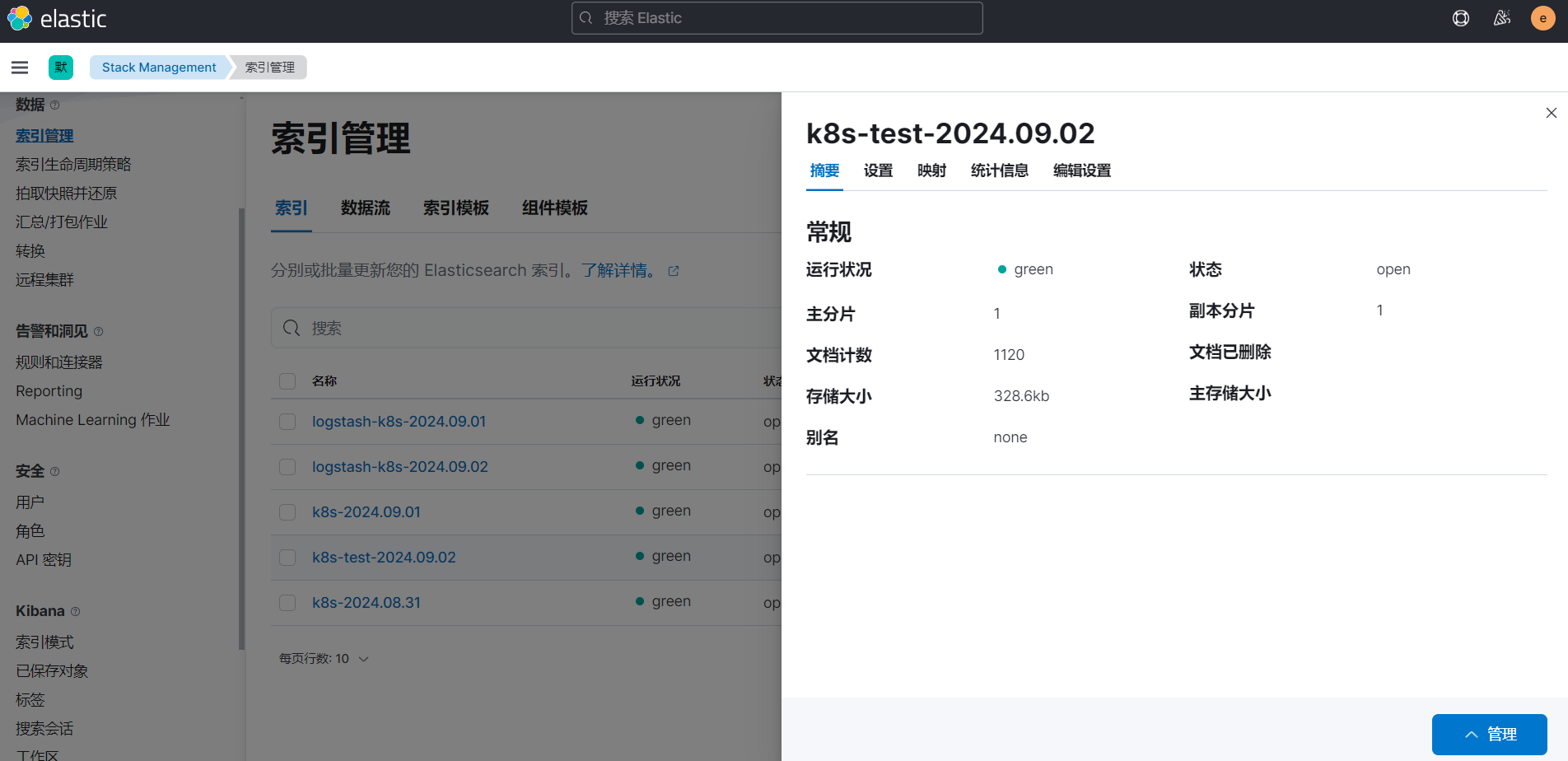
这样我们就实现了自定义索引名称,当然你也可以使用 Pod 名称、容器名称、命名空间名称来作为索引的名称,这完全取决于你自己的需求。