Ceph crush算法进阶 (九)
场景:集群内有固态和机械硬盘 如何让不重要的业务放到机械盘。 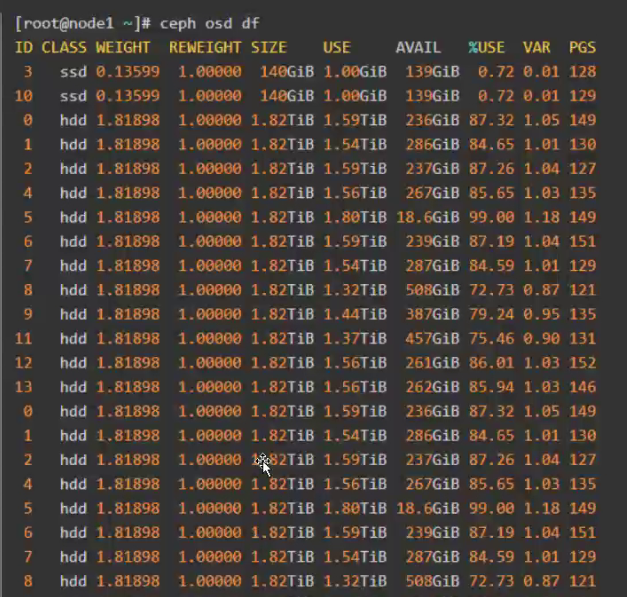
Ceph 集群中由 mon 服务器维护的的五种运行图:
- Monitor map 监视器运行图
- OSD map OSD运行图 各个每隔6s汇报状态同时监控其他OSD的状态,超过20秒就会被踢出去
- PG map PG运行图 (一个存储池有哪些pg)
- Crush map (Controllers replication under scalable hashing) 可控的、可复��制的、可伸缩的一致性hash算法。crush运行图,当新建存储池时会基于OSD map创建出新的PG组合列表用于存储数据
- MDS map cephfs metadata运行图
数据的访问:
obj-->pg hash(oid)%pg=pgid 先将文件计算成一个hash值,这个数取pg数量的余数 最终得到分配到那个pg中
Obj-->OSD crush 根据当前的mon运行图返回pg内的最新的OSD组合,数据即可开始往主的写然后往副本OSD同步
crush 算法针对目的节点的选择:
目前有5种算法来实现节点的选择,包括Uniform、List、 Tree、 Straw、 Straw2, 早期版
本使用的是ceph项目的发起者发明的算法straw,目前已经发展到straw2版本。
抽签算法
9.1 PG与OSD映射调整
默认情况下,crush算法自行对创建的pool中的PG分配OSD,但是可以手动基于权重设置 crush 算法分配数据的倾向性, 比如1T 的磁盘权重是1, 2T 的就是2, 推荐使用相同大小的设备。
调整的方法有两种:
1. 调整weight值
- 调整reweight值
9.1.1 查看当前状态
ceph osd df
基于存储空间
**weight **表示设备(device)的容量相对值,比如 1TB 对应1.00 ,那么500G的 OSD 的 weight 就应该是0.5, weight 是基于磁盘空间分配PG的数量,让crush算法尽可能往磁盘空间大的OSD多分配OSD。往磁盘空间小的OSD分配较少的OSD。
那个磁盘快满了调整一下��释放资源
**Reweight **参数的目的是重新平衡 ceph的CRUSH算法随机分配的PG,默认的分配是概率上的均衡,即使OSD都是一 样的磁盘空间也会产生一些PG分布不均匀的情况, 此时可以通过调整reweight参数,让ceph集群立即重新平衡当前磁盘的PG,以达到数据均衡分布的目的,REWEIGHT 是PG已经分配完成,要在cepg集群重新平衡PG的分布。
9.1.2 修改WEIGHT并验证
#修改某个指定ID的osd的权重 调整完立即生效
root@ceph-deploy:~# ceph osd crush reweight osd.10 1.5
#验证OSD权重:
root@ceph-deploy:~# ceph osd df
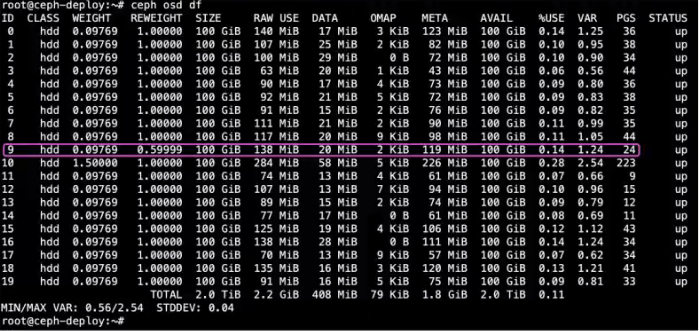
9.1.3 修改 REWEIGHT 并验证
OSD 的 REWEIGHT的值默认为1 ,值可以调整,范围在0~1之间,值越低PG越小,如果调整了任何一个OSD的REWEIGHT值,那么OSD的PG会立即和其它OSD进行重新平衡,即数据的重新分配,用于当某个OSD的PG相对较多需要降低其PG 数量的场景。
root@ceph-deploy:~# ceph osd reweight 9 0.6
9.2 crush运行图管理
通过工具将 ceph 的crush 运行图导出并进行编辑,然后导入
9.2.1 导出crush运行图
注: 导出的 crush 运行图为二进制格式,无法通过文本编辑器直接打开,需要使用crushtool工具转换为文本格式后才能通过vim等文本编辑宫工具打开和编辑。
root@ceph-deploy:~# mkdir /data/ceph -p
#导出
root@ceph-deploy:~# ceph osd getcrushmap -o /data/ceph/crushmap
67
9.2.2 将运行图转换为文本:
导出的运行图不能直接编辑,需要转换为文本格式再进行查看与编辑
root@ceph-deploy:~# apt install ceph-base
root@ceph-deploy:~# crushtool -d /data/ceph/crushmap > /data/ceph/crushmap.txt
root@ceph-deploy:~# file /data/ceph/crushmap.txt
/data/ceph/crushmap.txt: ASCII text
9.2.3 编辑文本
#自定义修改
root@ceph-deploy:~# vim /data/ceph/crushmap.txt
# begin crush map
#可调整的crush map参数
tunable choose local tries 0
# devices #当前的设备列表
device 0 osd.0 class hdd
device 1 osd.1 class hdd
# types #当前支持的bucket类型 以什么为单位
type 0 osd #osd守护进程,对应到一个磁盘设备
type 1 host #一个主机 (默认放在不同的主机)
type 2 chassis #刀片服务器的机箱
type 3 rack #包含若干个服务器的机柜/机架
type 4 row #包含若干个机柜的一排机柜
type 5 pdu #机柜的接入电源插座
type 7 room #包含若干机柜的房间,一个数据中心有好多这样的房间组成
type 8 datacenter #一个数据中心或IDS
type 9 region #一个区域,比如AWS宁夏中卫数据中心
type 10 root #bucket分层的最顶部,根算法
item osd.0 weight 0.098 #osd0权重比例,crush 会自动根据磁盘空间计算,不同的磁盘空间的权重不一样
tem osd.1 weight 0.098
tem osd.2 weight 0.098
tem osd.3 weight 0.098
tem osd.4 weight 0.098
}
...
root default { #根的配置
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 3.256
alg straw2
hash 0 # rjenkins1
item ceph-node1 weight 0.488
item ceph-node2 weight 0.488
item ceph-node3 weight 0.488
item ceph-node4 weight 0.488
}
# buckets
host ceph-node1 { 类型Host 名称为ceph-node1
id -3 # do not change unnecessarily #ceph生成的OSD ID,非必要不要改
id -4 class hdd # do not change unnecessarily
# weight 0.488
alg straw2 #crush算法,管理OSD角色
hash 0 # rjenkins1 #使用是哪个hash算法,0表示选择rjenkins1这种hash算法
item osd.0 weight 0.098 #osd 0 权重比例,crush 会自动根据磁盘空间计算,不同的磁盘空间的权重不一样
item osd.1 weight 0.098
item osd.2 weight 0.098
item osd.3 weight 0.098
item osd.4 weight 0.098
}
host ceph-node2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.461
alg st raw2
hash 0 # rjenkins1
item osd.5 weight 0.098
item osd.6 weight 0.098
item osd.7 weight 0.070
item osd.8 weight 0.098
item osd.9 weight 0.098
}
root default { #根的配置
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 3.256
alg straw2
hash0 # rjenkins1
item ceph-node1 weight 0.488
item ceph-node2 weight 0.488
item ceph-node3 weight 0.488
item ceph-node4 weight 0.488
}
# rules
rule replicated _rule { #副本池的默认配置
id 0
type replicated
min_size 1
max_size 10 #默认最大副本为10
step take default #基于default定义的主机分配OSD
step chooseleaf firstn 0 type host #选择主机,故障域类型为主机
step emit #弹出配置即返回给客户端
}
rule erasure-code { #纠删码池的默认配置
type erasure
min_size 3
max_size 4
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default
step chooseleaf indep 0 type host
step emit
}
# rules
rule replicated rule {
id 0
type rep Licated
min_size 1
max_size 6 #修改最大副本数
step take default
step chooseleaf firstn 0 type host
step emit
}
9.2.3 将文本转换为crush格式
root@ceph-deploy:~# crushtool -c /data/ceph/crushmap.txt -o /data/ceph/newcrushmap
9.2.4 导入新的crush
导入的运行图会立即覆盖原有的运行图并立即生效.
root@ceph-deploy:~# ceph osd setcrushmap -i /data/ceph/newcrushmap
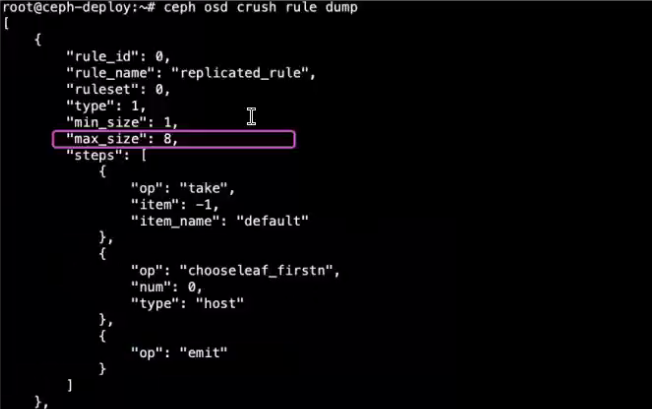
9.2.5 验证crush运行图是否�生效
root@ceph-deploy:~# ceph osd crush rule dump
[
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 6,
9.3 crush数据分类管理
Cephcrush 算法分配的PG的时候可以将PG分配到不同主机的OSD上,以实现以主机为单位的高可用,这也是默认机制,但是无法保证不同PG位于不同机柜或者机房的主机。
如果要实现基于机柜或者是更高级的IDC等方式的数据高可用,而且也不能实现A项目的数据在SSD,B项目的数据在机械磁盘,如果想要实现此功能则需要导出crush运行图并手动编辑,之后再导入并覆盖原有的crush运行图。
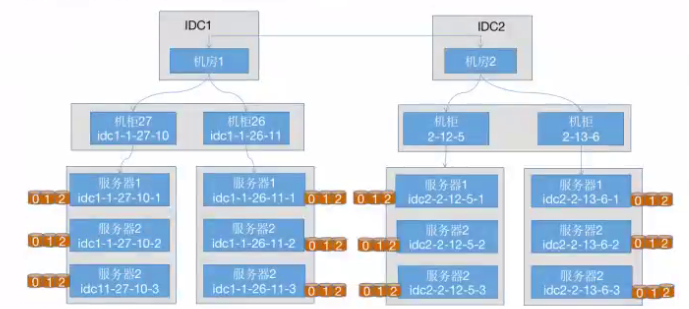
9.3.1 导出cursh运行图
root@ceph-deploy:~# mkdir /opt/ceph/
root@ceph-deploy:~# ceph osd getcrushmap -o /opt/ceph/crushmap
68
9.3.2 将运行图转换为文本
root@ceph-deploy:~# crushtool -d /opt/ceph/crushmap > /opt/ceph/crushmap.txt
root@ceph-deploy:- # file /opt/ceph/crushmap.txt
/opt/ceph/crushmap.txt: ASCII text
9.3.3 添加自定义配置
root@ceph-deploy:~# cat topt/ceph/crushmap.txt
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
device 9 osd.9 class hdd
device 10 osd.10 class hdd
device 11 osd.11 class hdd
device 12 osd.12 class hdd
device 13 osd.13 class hdd
device 14 osd.14 class hdd
device 15 osd.15 class hdd
device 16 osd.16 class hdd
device 17 osd.17 class hdd
device 18 osd.18 class hdd
device 19 osd.19 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host ceph-node1 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.490
alg straw2
hash0 # rjenkins1
item osd.0 weight 0.098
item osd.1 weight 0.098
item osd.2 weight 0.098
item osd.3 weight 0.098
}
host ceph-node2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.490
alg straw2
hash0 # rjenkins1
item osd.5 weight 0.098
item osd.6 weight 0.098
item osd.7 weight 0.098
item osd.8 weight 0.098
item osd.9 weight 0.098
}
host ceph-node3 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 1.792
alg straw2
hash 0 # rjenkins1
item osd.10 weight 1.400
item osd.11 weight 0.098
item osd.12 weight 0.098
item osd.13 weight 0.098
item osd.14 weight 0.098
}
host ceph-node4 {
id -9 # do not change unnecessarily
id -10 class hdd # do not change unnecessarily
# weight 0.490
alg straw2
hash 0 # rjenkins1
item osd.15 weight 0.098
item osd.16 weight 0.098
item osd.17 weight 0.098
item osd.18 weight 0.098
item osd.19 weight 0.098
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 3.255
alg straw2
hash 0 # rjenkins1
item ceph-node1 weight 0.488
item ceph-node2 weight 0.488
item ceph-node3 weight 1.791
item ceph-node4 weight 0.488
}
#前面是机械节点,后面定义ssd节点,ID不能冲突
#magedu ssd node
host ceph-ssdnode1 {
id -103 # do not change unnecessarily
id -104 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.098
}
host ceph-ssdnode2 {
id -105
# do not change unnecessarily
id -106 class hdd
# do not change unnecessarily
# weight 0.098
alg straw2
hash0 # rjenkins1
item osd.5 weight 0.098
}
host ceph-ssdnode3 {
id -107 # do not change unnecessarily
id -108 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.10 weight 0.098
}
host ceph-ssdnode4 {
id -109 # do not change unnecessarily
id -110 class hdd # do not change unnecessarily
# weight 0.098
alg straw2
hash 0 # rjenkins1
item osd.15 weight 0.098
}
#magedu bucket 把定义node加进来
root ssd {
id -127 # do not change unnecessarily
id -111 class hdd # do not change unnecessarily
# weight 1.952
alg straw
hash 0 # rjenkins1
item ceph-ssdnode1 weight 0.488
item ceph-ssdnode2 weight 0.488
item ceph-ssdnode3 weight 0.488
item ceph-ssdnode4 weight 0.488
}
#magedu ssd-rules
rule magedu_ssd_rule {
id 20
type replicated #类型副本池
min_size 1
max_size 5
step take ssd #定义使用的bucket
step chooseleaf firstn 0 type host #选择方法 选择当前副本数个主机下的OSD, 高可用类型host
step emit
}
## chooseleaf表示在确定故障域后,还必须选出该域下面的OSD节点
rule replicated rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
rule erasure-code {
id 1
type erasure
min_size 3
max_size 4
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default
step chooseleaf indep 0 type host
step emit
}
rule erasure-code {
id 1
type erasure
min_size 3
max_size 4
step set_chooseleaf_tries 5
step set_choose_tries 100
step take default
step chooseleaf indep 0 type host
step emit
# end crush map
rule data {
ruleset 0 //ruleset 编号
type replicated //多副本类型
min_size 1 //副本最小值为1
max_size 10 //副本最大值为10
step take default //选择default buket输入{take(default)}
step chooseleaf firstn 0 type host //选择当前副本数个主机下的OSD{select(replicas, type)}
step emit //输出将要��分布的bucket的列表{emit(void)}
}
9.3.4 转换为crush二进制格式
root@ceph-deploy:~# crushtool -C /opt/ceph/crushmap.txt -o /opt/ceph/newcrushmap
9.3.5 导入新的crush运行图
root@ceph-deploy:~# ceph osd setcrushmap -i /opt/ceph/crushmap
70
9.3.6 验证crush运行图是否生效
root@ceph-deploy:~# ceph osd crush rule dump
9.3.7 测试创建存储池
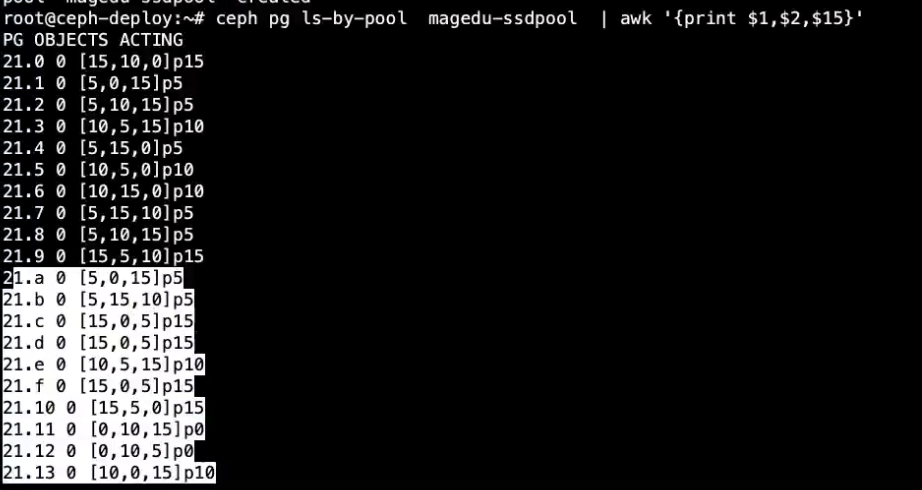
root@ceph-deploy:~# peph osd pool create magedu-ssdpool 32 32 magedu_ssd_rule
pool 'magedu-ssdpool' created
#指定存储池 rule 默认是defuse
9.3.8 验证pgp状态
ceph pg ls-by-pool magedu-ssdpool awk '{print $1, $2,$15} '