Ceph理论详解 (一)
分布式存储简介
分布式存储的数据分为数据和元数据,元数据即是文件的属性信息(文件名、权限(属主、属组)、大小、时间戳等),在分布式存储中当客户端或者应用程序产生的客户端数据被写入到分布式存储系统的时候,会有一个服务(Name Node)提供文件元数据的路由功能,告诉应用程序去哪个服务器去请求文件内容,然后再有(Data Node)提供数据的读写请求及数据的高可用功能。

1. Ceph 概述
Ceph 是一个开源的分布式存储系统,同时支持对象存储、块设备、文件系统。
Ceph 是一个对象(object)式存储系统,它把每一个待管理的数据流(文件等数据)切分为一到多个固定大小(默认 4 兆)的对象数据,并以其为原子单元(原子是构成元素的最小单元)完成数据的读写。
对象数据的底层存储服务是由多个存储主机(host)组成的存储集群,该集群也被称之为RADOS(reliable automatic distributed obiect store)存储集群,即可靠的、自动化的、分布式的对象存储系统。
LibRADOS 是 RADOS 存储集群的 API,支持 C/C++/JAVA/python/ruby/php 等编程语言客户端。

如果每台服务器上有4块磁盘,那么就会自动启动四个OSD进程。并且一块磁盘可以用于多个OSD存储池。
为何要用Ceph?
- 高性能 :
-
摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
-
考虑了容灾的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
-
能够支持上千个存储节点的规模,支持TB到PB级的数据。
- 高可用 :
-
副本数可以灵活控制
-
支持故障域分隔,数据强一直性
-
多故障场景�自动进行修复自愈
-
没有单点故障,自动管理,高可扩展性
- 去中心化 :
-
扩展灵活
-
随着节点增加而线性增长
- 特性丰富 :
- 支持三种存储接口 : 块存储、文件存储、对象存储
- 支持自定义接口,支持多种语言驱动。
1.1 Ceph 的发展史
Ceph 项目起源于 于2003 年在加州大学圣克鲁兹分校攻读博士期间的研究课题 (Lustre 环境中的可扩展问题)。
Lustre 是一种平行分布式文件系统,早在 1999 年,由皮特·布拉姆(Peter Braam)创建的集群文件系统公司(Cluster File Systems inc)开始研发,并于2003 年发布 Lustre 1.0 版本。
2007 年 Sage Weil(塞奇·威尔)毕业后,Sage Weil 继续全职从事 Ceph 工作 , 2010 年3月19 日,Linus Torvalds 将 Ceph 客户端合并到 2010 年5月16 日发布的 Linux 内核版本 2.6.34, 2012年Sage Weil 创建了Inktank Storage 用于为 Ceph 提供专业服务和支持,2014年4月Redhat 以1.75亿美元收购inktank 公司并开源。
1.2 Ceph 的设计思想
Ceph 的设计旨在实现以下目标:
- 每一组件皆可扩展。
- 无单点故障。
- 基于软件(而非专用设备)并且开源(无供应商锁定)在现有的廉价硬件上运行。
- 尽可能自动管理,减少用户干预。
1.3 Ceph的版本历史
Ceph 的第一个版本是 0.1,发布目期为 2008 年1月,多年来 Ceph 的版本号一直采用递归更新的方式没变直到 2015 年4月 0.941(Hammer 的第一个修正版)发布后,为了避免0.99(以及0.100 或 1.00),后期的命名方式发生了改变:
- x.0.z- 开发版 (给早期测试者和勇士们)
- x.1.z - 候选版 (用于测试集群、高手们)
- x.2.z- 稳定、修正版 (给用户们)
x将从9 算起它代表 Infernalis(首字母I是英文单词中的第九个字母),这样我们第九个发布周期的第一个开发版就是 9.0.0,后续的开发版依次是 9.0.0->9.0.1->9.0.2 等,测试版本就是9.1.0->9.1.1->9.1.2,稳定版本就是9.2.0->9.2.1->9.2.2。

2. Ceph 集群角色定义
一个Ceph集群的组成部分:
- 若干的 Ceph OSD(对象存储守护程序)
- 至少需要一个 Ceph Monitors 监视器 (1,3,5,7...)
- 两个或以上的Ceph管理器managers,运行Ceph文件系统客户端时,还需要高可用的Ceph
- Metadata Server(文件系统元数据服务器)
- RADOS cluster:由多台host 存储服务器组成的Ceph 集群
- OSD(Object Storage Daemon):每台存储服务器的磁盘组成的存储空间
- Mon(Monitor):Ceph 的监视器,维护OSD 和PG 的集群状态,一个Ceph 集群至少要有一个mon,可以是一三五��七等等这样的奇数个。
- Mgr(Manager):负责跟踪运行时指标和Ceph 集群的当前状态,包括存储利用率,当前性 能指标和系统负载等。
Ceph OSDs: Ceph OSD 守护进程 (Ceph OSD)的功能是存储数据,处理数据的复制、恢复、回填、在均衡,并通过查其OSD 守护进程的心跳来向Ceph Monitors 提供一些监控信息。当Ceph存储集群设定为2个副本时,至少需要2个OSD守护进程。这样集群才能达到 active+clean 状态(Ceph 默认有3个副本,但你可以调整副本数)。
Monitors: Ceph Monitor 维护着展示集群状态的各种图表、包括监视图、OSD图、归置组(PG)图、和CRUSH图。Ceph保存着发生在Monitors、OSD和PG上的每一次状态变更的历史记录信息(称为epoch)。
MDSs: Ceph元数据服务器(MDS)为Ceph文件系统存储元数据(也就是说,Ceph块设备和Ceph对象存储不使用MDS)。元数据服务器使得POSIX文件系统的用户们,可以在不对 Ceph 存储集群造成负担的前提下,执行诸如 ls、find 等基本命令。
Ceph把客户端数据保存为存储池内的对象。通过使用CRUSH算法,Ceph可以计算出哪个归置组(PG)应该持有指定的对象(Object),然后进一步计算出哪个OSD守护进程持有该归置组。CRUSH算法使得Ceph存储集群能够动态地伸缩、再均衡和修复。

2.1 Monitor(Ceph-mon) Ceph 监视器
在一个主机上运行的一个守护进程,��用于维护集群状态映射(maintains maps of the cluster state),比如Ceph 集群中有多少存储池、每个存储池有多少PG 以及存储池和PG的映射关系等, monitor map, manager map, the OSD map, the MDS map, and the CRUSH map,这些映射是Ceph 守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的身份验证(认证使用CephX 协议)。通常至少需要三个监视器才能实现冗余和高可用性。
监视器,维护集群状态的多种映射,同时提供认证和日志记录服务,包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。
并且存储当前版本信息以及最新更改信息,通过 "Ceph mon dump"查看 monitor map。
Ceph osd unset noout
#重启服务器不踢出磁盘,重启前设置
Ceph -s
2.2 Managers(Ceph-mgr)的功能:
在一个主机上运行的一个守护进程,Ceph Manager 守护程序(Ceph-mgr)负责跟踪运行时指标和Ceph 集群的当前状态,包括存储利用率,当前性能指标和系统负载。Ceph Manager 守护程序还托管基于python 的模块来管理和公开Ceph 集群信息,包括基于Web的Ceph 仪表板和REST API。
高可用性通常至少需要两个管理器。
2.3 Ceph OSDs(对象存储守护程序Ceph-osd)
即对象存储守护程序,但是它并非针对对象存储。提供存储数据,操作系统上的一个磁盘就是一个OSD 守护程序。
是物理磁盘驱动器,将数据以对象的形式存储到集群中的每个节点的物理磁盘上。
OSD负责存储数据、处理数据复制、恢复、回(Backfilling)、再平衡。完成存储数据的工作绝大多数是由 OSD daemon 进程实现。
在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。
此外OSD还对其它OSD进行心跳检测,检测结果汇报给Monitor。
通常至少需要3 个Ceph OSD 才能实现冗余和高可用性。
2.4 MDS(Ceph 元数据服务器Ceph-mds)
Ceph 元数据,主要保存的是Ceph文件系统(NFS/CIFS)的元数据。
注意:Ceph的块存储和Ceph对象存储都不需要MDS。
2.5 Ceph 的管理节点
1.Ceph 的常用管理接口是一组命令行工具程序,例如rados、Ceph、rbd 等命令,Ceph 管理员可以从某个特定的Ceph-mon 节点执行管理操作。
2.推荐使用部署专用的管理节点对Ceph 进行配置管理、升级与后期维护,方便后期权限管理,管理节点的权限只对管理人员开放,可以避免一些不必要的误操作的发生。
3.Ceph的逻辑架构

- pool 存储池、分区,存储池的大小取决于底层的存储空间,我们在创建pool存储池时需要指定pg的个数,来创建pg。创建pg需要用到crush算法,crush算法决定了pg与osd daemon的对应关系,所以说,在客户端往ceph中写入数据之前,pg与osd daemon的对应关系是已经确定的。虽然是确定的,但是pg与osd daemon的对应关系是动态的。
- PG(placement group) pg是ceph中分配数据的最小单位,一个pg内包含多个osd daemon,一个pool 中有多少个PG 可以通过公式计算。
- OSD(Object Storage Daemon,对象存储�设备) : 每一块磁盘都是一个osd,一个主机由一个或多个osd 组成。
3.1 pool存储池详解
Ceph的pool有四大属性
- 所有性和访问权限
- 对象副本数目,默认pool池中的一个pg只包含两个osd daemon,即一份数据交给pg后会存下2个副本,生产环境推荐设置为3个副本。
- pg数目,pg是pool的存储单位,pool的存储空间就由pg组成
- crush规则集合。
3.2 pg 数与osd daemon之间对应关系的影响
创建pool时需要确定其pg的数目,在pool被创建后也可以调整该数字,但是增加池中的pg数是影响ceph集群的重大事件之一,在生产环境中应该避免这么做。因为pool中的pg的数目会影响到:
- 数据的均匀分布性
- 资源消耗:pg作为一个逻辑实体,它需要消耗一定的资源,包括内存,CPU和带宽,太多的pg的话,则占用资源会过多
- 清理时间:Ceph的清理工作是以pg为单位进行的。如果一个pg内的数据太多,则其清理时间会很长
- 数据的持久性:pool中的pg个数应该随着osd daemon的增多而增多,这样crush算法可以将pg和osd的对应关系尽量均匀一些,降低同一个osd属于很多个pg的几率,如果一个osd真的属于很多很多pg,这样可能会很糟糕,可能会出现如下情况:
假设我们pool副本的size为3,则表示每一个pg将数据存放在3个osd上。一旦某个osd daemon挂掉,因为一个osd daemon同时属于很多个pg,则此时会出现很多pg只有2个副本的情况,这个时候通过crush算法开始进行数据恢复。在数据恢复的过程中,因为数据量过大,又有一个osd daemon(也属于很多很多pg)扛不住压力也崩溃掉了,那么将会有一部分pg只有一个副本。这个时候通过crush算法再次开始进行数据恢复,情况继续恶化,如果再有第三个osd daemon挂掉,那么就可能会出现部分数据的丢失。
由此可见,osd daemon上的pg组数目:
不能过小,过小则数据分布不均匀 不能过大,过大则一个osd daemon挂掉影响范围会很广,这会增大数据丢失的风险
osd daemon上的pg组数目应该是在合理范围内的,我们无法决定pg组与osd daemon之间的对应关系,这个是由crush算法决定的。但是我们可以在创建pool池时,可以指定pool池内所包含pg的数量,只要把pg的数量设置合理,crush算法自然会保证数据均匀。
3.3 指定pool池中pg的数量
如何算出一个pool池内应该有多少个pg数?
- Target PGs per OSD:crush算法为每个osd daemon分配的pg数(官网建议100或200个)
- OSD#:osd daemon的总数
- %DATA:该存储池的空间占ceph集群整体存储空间的百分比
- Size:pool池中的副本数
计算公式:
(Target PGs per OSD)✖(OSD#)✖(%DATA)/Size
如果如果ceph集群很长一段时间都不会拓展,我们osd daemon的总数为9,该存储池占用整个ceph集群整体存储空间的百分比为1%(10G/1000G),pool池中的副本数为3个,那么我们在pool池中设置pg的数量为多少合理?
100 * 9 * 0.01 / 3 = 3 (个)
官网也给出了一些参考原则
osd daemon的总数少于5个,建议将pool中的pg数设为128 osd daemon的总数5到10个,建议将pool中的pg数设为512 osd daemon的总数10到50个,建议将pool中的pg数设为4093
osd daemon的总数为50个以上,我们可以使用官网的工具进行计算,来确定pool池中pg的个数。ceph官网计算工具网址:https://ceph.com/pgcalc/
3.4 Ceph中pool池的两种类型
-
Replicated pool(默认) 副本型pool,通过生产对象的多份拷贝 优点 : 保证了数据的安全 缺点 : 浪费空间,如果设置的pg对应三个副本,那么空间只能用到原来空间的三分之一
-
Erasure-coded pool 特点 : 没有副本,可以把空间百分之百利用起来,但是没有副本功能(无法保证数据的安全) 不支持ceph的压缩,不支持ceph垃圾回收的功能等
3.5 Ceph网络划分
Ceph推荐主要使用两个网络,这么做,注意从性能(OSD节点之间会有大量的数据拷贝操作)和安全性(两网分离)考虑。
- 前端(南北)网络 : 连接客户端和集群
- 后端(东西)网络 : 连接ceph各个存储节点

4. Ceph数据写入流程
Ceph 集群部署好之后,要先创建存储池才能向Ceph 写入数据,文件在向Ceph 保存之前要先进行一致性hash 计算,计算后会把文件保存在某个对应的PG 的,此文件一定属于某个pool 的一个PG,在通过PG 保存在OSD 上。数据对象在写到主OSD 之后再同步对从OSD 以实现数据的高可用。
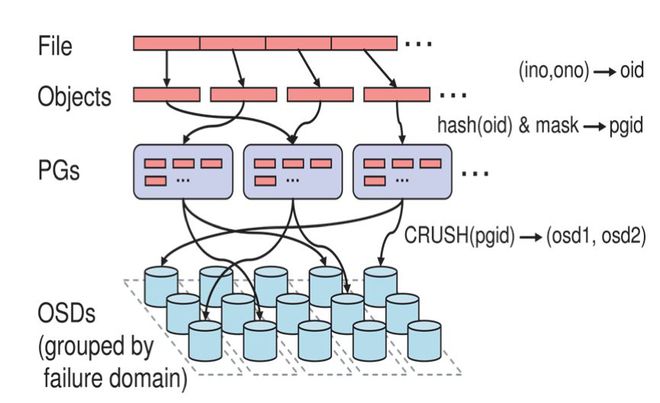
第一步: 计算文件到对象的映射:
File放到Ceph集群后,先把文件进行分割,分割为等大小的小块,小块叫object(默认为4M)
计算文件到对象的映射,假如file 为客户端要读写的文件,得到oid(object id) = ino + ono
ino:inode number (INO),File 的元数据序列号,File 的唯一id。
ono:object number (ONO),File 切分产生的某个object 的序号,默认以4M 切分一个块大小。
比如:一个文件FileID为A,它被切成了两个对象,一个对象编号0,另一个编号1,那么这两个文件的oid则为A0与A1。
1)由Ceph集群指定的静态Hsah函数计算Object的oid,获取到其Hash值。
2)将该Hash值与mask进行与操作,从而获得PG ID。
第二步:通过hash 算法计算出文件对应的pool 中的PG:
小块跟据一定算法跟规律,算法是哈希算法,放置到PG组里。
通过一致性HASH 计算Object 到PG, Object -> PG 映射hash(oid) & mask-> pgid
第三步: 通过CRUSH 算法把对象映射到PG 中的OSD:
再把PG放到OSD里面。
通过CRUSH 算法计算PG 到OSD,PG -> OSD 映射:[CRUSH(pgid)->(osd1,osd2,osd3)]
第四步:PG 中的主OSD 将对象写入到硬盘。
第五步: 主OSD 将数据同步给备份OSD,并等待备份OSD 返回确认。
第六步: 备份OSD返回确认后,主OSD 将写入完成返回给客户端。
Ceph中数据写入,会有三次映射
(1)File -> object映射
(2)Object -> PG映射,hash(oid) & mask -> pgid
(3)PG -> OSD映射,CRUSH算法

5.元数据的保存方式
Ceph 对象数据的元数据信息放在哪里呢? 对象数据的元数据以 key-value 的形式存在, 在RADOS 中有两种实现:xattrs 和 omap:
Ceph 可选后端支持多种存储引擎,比如 filestore,kvstore,memstore,目前是以 kvstore 的 形式存储对象数据的元数据信息。
5.1 xattr 扩展属性
是将元数据保存在对象对应文件数据中并保存到系统磁盘上,这要求支持对象存储的 本地文件系统(一般是 XFS)支持扩展属性。元数据和数据放一起
5.2 omap(object map 对象映射)
omap是 object map 的简称,是将元数据保存在本地文件系统之外的独立 key-value 存储 系统中,在使用 filestore 时是 leveldb,在使用 bluestore 时是 rocksdb,由于 filestore 存在功能问题(需要将磁盘格式化为 XFS 格式)及元数据高可用问题等问题,因此在目前 Ceph 主要使用 bluestore。
5.3 Filestore与LevelDB 存储系统
Ceph 早期基于 filestore 使用 google 的 levelDB 保存对象的元数据,LevelDb 是一个持久化存 储的 KV 系统,和 Redis 这种内存型的 KV 系统不同,LevelDb 不会像 Redis 一样将数据放在内存从而占用大量的内存空间,而是将大部分数据存储到磁盘上,但是需要把磁盘上的 levelDB 空间格式化为文件系统(XFS).
FileStore 将数据保存到与 Posix 兼容的文件系统(例如 Btrfs、XFS、Ext4)。在 Ceph 后端使用传统的 Linux 文件系统尽管提供了一些好处,但也有代价,如性能、 对象属性与磁盘本地文 件系统属性匹配存在限制等。
Filestore 数据写入的过程
1、先把要写入的数据全部封装成一个事务,其整理作为一条日志,写入日志磁盘(一般把 日志放在 ssd 上提高性 能),这个过程叫日志的提交(journalsubmit)。
2、把数据写入对象文件的磁盘中(也就是 OSD 的磁盘中),这个过程叫日志的应用(journal apply)。这个过程不一定写入磁盘,有可能缓存在本地文件系统的 page cache 中。 当系统在日志提交的过程中出错,系统重启后,直接丢弃不完整的日志条目,该条日志对应 的实际对象数据并没有修改,数据保证了一致性。当日志在应用过程中出错,由于日志已写 入到磁盘中,系统重启后,重放(replay)日志,这样保证新数据重新完整的写入,保证了 数据的一致性
FileStore 日志的三个阶段
日志的提交(journal submit):日志写入日志磁盘。
日志的应用(journal apply):日志对应的修改更新到对象的磁盘文件中。这个过程不一定写入 磁盘,有可能缓存在本地文件系统的 page cache 中。
日志的同步(journal sync 或者 journal commit):确定日志对应的修改操作已经刷到磁盘中
5.4 BlueStore 与 RocksDB 存储系统
由于 levelDB 依然需要需要磁盘文件系统的支持,后期 Facebok 对 levelDB 进行改进为 RocksDB,RocksDB 将对象数据的元数据保存在 RocksDB,但是 RocksDB 的数据又放在哪里呢?
放在内存怕丢失,放在本地磁盘但是解决不了高可用,Ceph 对象数据放在了每个 OSD 中,那么就在在当前 OSD 中划分出一部分空间,格式化为 BlueFS 文件系统用于保存 RocksDB 中的元数据信息(称为 BlueStore),并实现元数据的高可用, BlueStore 最大的特点是构建在裸磁盘设备之上,并且对诸如 SSD 等新的存储设备做了很多优化工作。
- 对全 SSD 及全 NVMe SSD 闪存适配
- 绕过本地文件系统层,直接管理裸设备,缩短 IO 路径
- 严格分离元数据和数据,提高索引效率。
- 期望带来至少 2 倍的写性能提升和同等读性能
- 增加数据校验及数据压缩等功能。
- 解决日志“双写”问题。
- 使用 KV 索引,解决文件系统目录结构遍历效率低的问题
- 支持多种设备类型。
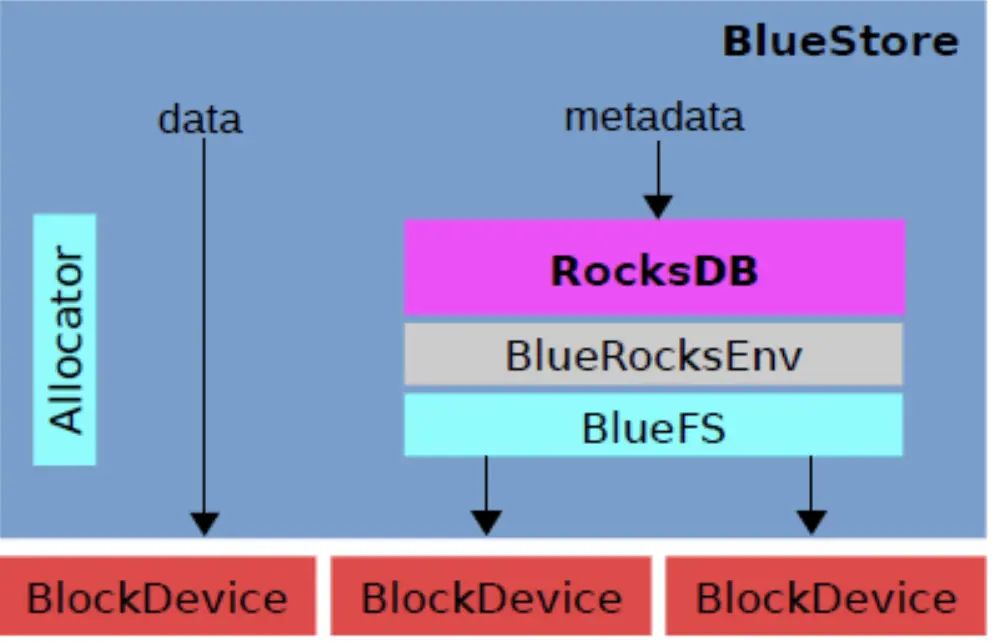
BlueStore 的逻辑架构如上图所示,模块的划分都还比较清晰,我们来看下各模块的作用:
-
Allocator:负责裸设备的空间管理分配。
-
RocksDB: 是 facebook 基于 leveldb 开发的一款 kv 数据库,BlueStore 将元数据全部存放至 RocksDB 中,这些元数据包括存储预写式日志、数据对象元数据、Ceph 的 omap 数 据信息、以及分配器的元数据 。
-
RocksDB 通过中间层 BlueRocksDB 访问文件系统的接口。这个文件系统与传统的 Linux 文件系统(例如 Ext4 和 XFS)是不同的,它不是在 VFS 下面的通用文件系统,而是一个用 户态的逻辑。BlueFS 通过函数接口(API,非 POSIX)的方式为 BlueRocksDB 提供类似文件系统的能力。
-
BlueRocksEnv:这是 RocksDB 与 BlueFS 交互的接口;RocksDB 提供了文件操作的接口 EnvWrapper(Env 封装器),可以通过继承实现该接口来自定义底层的读写操作,BlueRocksEnv 就是继承自 EnvWrapper 实现对 BlueFS 的读写。
-
BlueFS:BlueFS是BlueStore针对RocksDB开发的轻量级文件系统,用于存放RocksDB产生的.sst 和.log 等文件。
-
BlockDecive:BlueStore 抛弃了传统的 ext4、xfs 文件系统,使用直接管理裸盘的方式;BlueStore 支持同时使用多种不同类型的设备,在逻辑上 BlueStore 将存储空间划分为三层:慢速(Slow) 空间、高速(DB)空间、超高速(WAL)空间,不同的空间可以指定使用不同的设备类型, 当然也可使用同一块设备
BlueStore 的设计考虑了 FileStore 中存在的一些硬伤,抛弃了传统的文件系统直接管理裸设备,缩短了 IO 路径,同时采用 ROW 的方式,避免了日志双写的问题,在写入性能上有了极大的提高。
6. CRUSH 算法简介
Controllers replication under scalable hashing :可控的、可复制的、可伸缩的一致性 hash 算法。
Ceph 使用 CURSH 算法来存放和管理数据,它是 Ceph 的智能数据分发机制。 Ceph 使用 CRUSH 算法来准确计算数据应该被保存到哪里,以及应该从哪里读取,和保存元数据不同,是CRUSH 按需计算出元数据,因此它就消除了对中心式的服务器/网关的需求,它使得 Ceph 客户端能够计算出元数据,该过程也称为CRUSH 查找,然后和 OSD 直接通信。
-
如果是把对象直接映射到 OSD 之上会导致对象与 OSD 的对应关系过于紧密和耦合,当 OSD 由于故障发生变更时将会对整个 Ceph 集群产生影响。
-
于是 Ceph 将一个对象映射到 RADOS 集群的时候分为两步走: 首先使用一致性 hash 算法将对象名称映射到 PG 然后将 PG ID 基于 CRUSH 算法映射到 OSD 即可查到对象。
-
以上两个过程都是以”实时计算”的方式完成,而没有使用传�统的查询数据与块设备的对应表的方式,这样有效避免了组件的”中心化”问题,也解决了查询性能和冗余问题。这使得 Ceph 集群扩展不再受查询的性能限制,CRUSH 算法由Mon节点计算,根据使用量相应增加Mon节点数量。
-
这个实时计算操作使用的就是 CRUSH 算法 Controllers replication under scalable hashing 可控的、可复制的、可伸缩的一致性 hash 算法。CRUSH 是一种分布式算法,类似于一致性 hash 算法,用于为 RADOS 存储集群控制数据的分配,