Ceph FS (七)
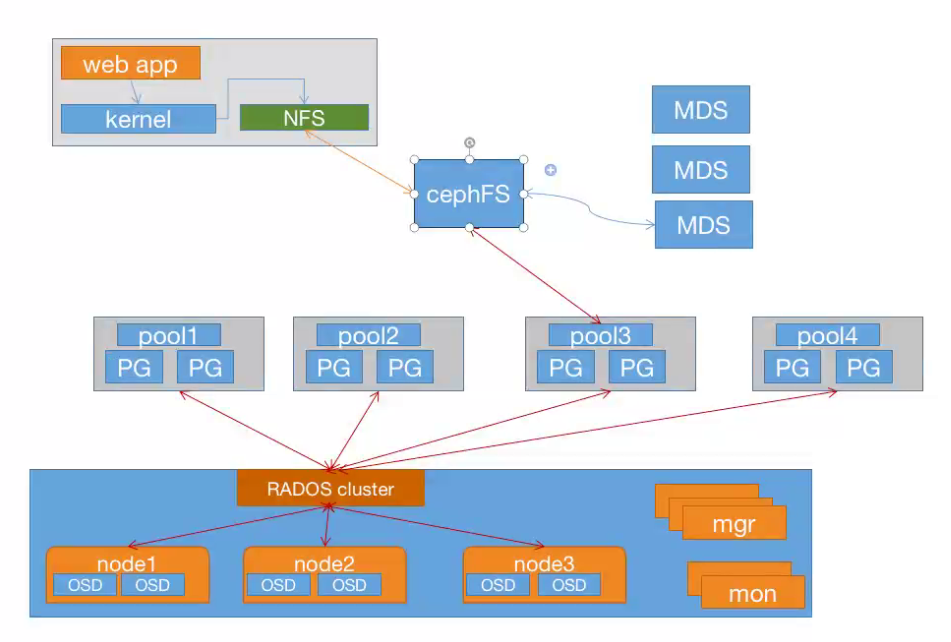
ceph FS即ceph filesystem,可以实现文件系统共享功能,客户端通过ceph协议挂载并使用ceph集群作为数据存储服务器。 (类似NFS)
Ceph FS需要运行Meta Data Services(MDS)服务,其守护进程为ceph-mds, ceph-mds
进程管理与Ceph FS上存储的文件相关的元数据,并协调对ceph存储集群的访问。
http://docs.ceph.org.cn/cephfs/
Ceph FS的元数据使用的动态子树分区,把元数据划分名称空间对应到不同的mds,写入元数据的时候将元数据按照名称保存到不同主mds上,有点类似于nginx中的缓存目录分层一样。但是最终元数据都会保存在ceph 元数据池中。

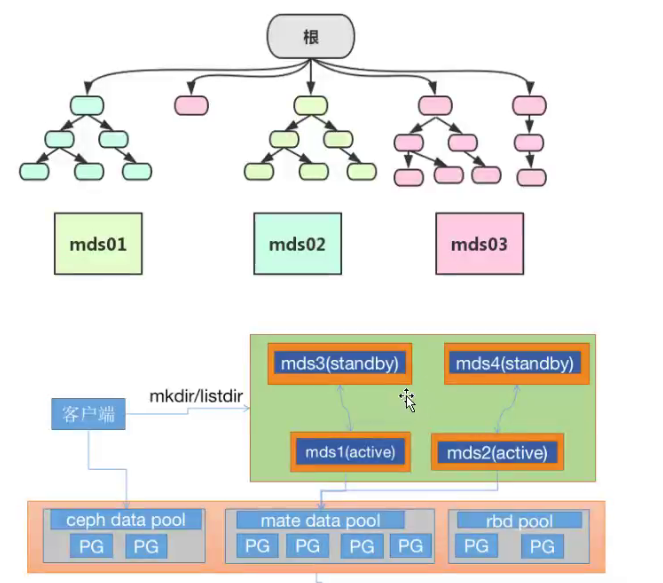
7.1 部署MDS 服务
如果要使用cephFS,需要部署cephfs服务。
Ubuntu:
root@ceph-mgr1:~# apt-cache madison ceph-mds
root@ceph-mgr1:~# apt install ceph-mds
Centos:
root@ceph-mgr1 ~]# yum install ceph-mds
$ ceph-deploy mds create ceph-mgr1
7.2 创建CephFS metadata和data存储池
使用CephFS之前需要事先于集群中创建一个文件系统,并为其分别指定元数据和数据相关的存储池。下面创建一一个名为cephfs的文件系统用于测试,它使用cephfs-metadata为元数据存储池,使用cephfs-data 为数据存储池。
#保存metadata的pool
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create cephfs-metadata 32 32
pool 'cephfs-metadata' created
#保存数据的pool
[ceph@ceph-deploy ceph-cluster]$ ceph osd pool create cephfs data 64 64
pool 'cephfs-data' created
(ceph@ceph-deploy ceph-cluster]$ ceph -s #当前ceph状态
cluster:
id:80a34e06-4458-4 1a8- 8d19-1 c0501152d69
health: HEALTH_ OK
services:
mon: 3 daemons, quorum ceph-mon1 ,ceph-mon2,ceph-mon3
mgr: ceph-mgr1(active), standbys: ceph-mgr2
osd: 12 osds: 12 up, 12 in
rgw: 1 daemon active
data:
pools: 8 pools, 224 pgs
objects: 278 objects, 302 MiB
usage: 13 GiB used, 1.2 TiB / 1.2 TiB avail
pgs: 224 active+clean
7.3 创建cephFS并验证
[ceph@ceph-deploy ceph-cluster]$ ceph fs new mycephfs cephfs-metadata cephfs-data
new fs with metadata pool 7 and data pool 8
[ceph@ceph-deploy ceph-cluster]$ ceph fs ls
name: mycephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]、
#查看指定cephFS状态
[ceph@ceph-deploy ceph-cluster$ ceph fs status mycephfs
7.4 验证cepfFS服务状态
#现在已经转变为活动状态
$ ceph mds stat
mycephfs-1/1/1 up {0=ceph-mgr1=up:active}
7.5 创建客户端账户
#创建账户
[ceph@ceph-deploy ceph-cluster]$ ceph auth add client.yanyan mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data'
added key for client.yanyan
#验证账户
[ceph@ceph-deploy ceph-cluster]$ ceph auth get client.yanyan
exported keyring for client.yanyan
[client.yanyan]
key = AQCxpdhfjQt1OxAAGe0mqTMveNu2ZMEem3tb0g==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
#创建用keyring文件
[ceph@ceph-deploy ceph-cluster]$ceph auth get client.yanyan -o ceph.client.yanyan.keyring
#创建key文件:
[ceph@ceph-deploy ceph-cluster]$ ceph auth print-key client.yanyan > yanyan.key
#验证用户的keyring文件
[ceph@ceph-deploy ceph-clusterl$ cat ceph.client.yanyan.keyring
[client.yanyan]
key = AQCxpdhfjQt1OxAAGe0mqTMveNu2ZMEem3tb0g==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rwx pool=cephfs-data"
7.6 安装ceph客户端
[root@ceph-client3 ~]# yum install epel-release -y
[root@ceph-client3~]# yum install htts://mirs.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release- 1-1.el7.noarch.rpm
7.7 同步客户端认证文件
[ceph@ceph-deploy ceph-cluster]$ scp ceph.conf ceph.client.yanyan.keyring yanyan.key root@172.31.6.203:/etc/ceph/
7.8 客户端验证权限
[root@ceph-client3 ~]# ceph --user yanyan -s
7.9 内核空间挂载ceph-fs
客户端挂载有两种方式,一是内核空间,二是用户空间,内核空间挂载需要内核支持ceph模块,用户空间挂载需要安装ceph-fuse。 内核> 2.6.34默认支持ceph
7.9.1 客户端通过key文件挂载
root@ceph-client3 ~]# mkdir /data
[root@ceph-client3~]# mount -t ceph 172.31.6.104:6789,172.31.6.105:6789,172.31.6.106:6789:/ /data -o name-yanyan,secretfile=/etc/ceph/yanyan.key
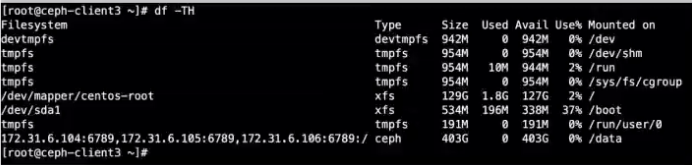
7.9.2 客户端通过key挂载
[root@ceph-client3 ~]# tail /etc/ceph/yanyan.key
AQCxpdhfjQt1OxAAGe0mqTMveNu2ZMEem3tb0g==
root@ceph-client3 ~]# umount /data/
[root@ceph-client3 ~]# mount -t ceph 172.31.6.104:6789,172.31.6.105:6789,172.31.6.106:6789:/ /data -o name=yanyan,secret=AQCxpdhfjQt1OxAAGe0mqTMveiJu2ZMEem3tb0g==
7.9.3 开机挂载
root@ceph-client3 ~]# cat /etc/fstab
172.31.6.104:6789,172.31.6.105:6789,172.31.6.106:6789:/ /data ceph defaults,name=yanyan,secretfile=/etc/ceph/yanyan.key,_netdev 0 0
[root@ceph-client3 ~]# mount -a
#secret挂载
172.31.6.101:6789,172.31.6.102:6789,172.31.6.103:6789:/ /data/cephfs ceph defaults ,name=yanyan,secret=AQBpxyBhUXlrIBAA9bW3UG2rdv6hQm0Is9MC7Q==,_netdev 0 0
7.9.4 客户端模块
客户端内核加载ceph.ko模块挂载cephfs文件系统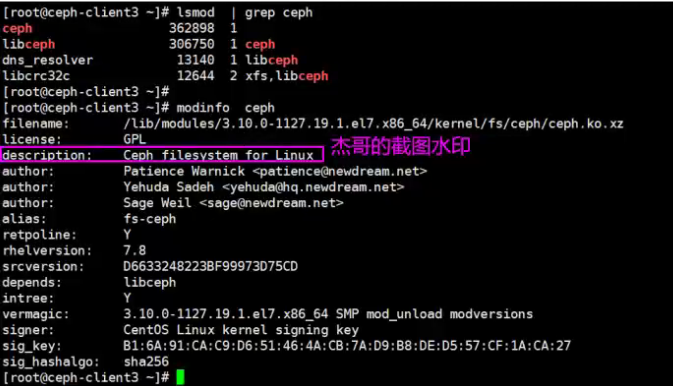
7.10 用户空间挂载ceph-fs
如果内核本较低而没有ceph模块,那么可以安装ceph-fuse 挂载,但是推荐使用内核模块挂载。
7.10.1 安装ceph-fuse
http://docs.ceph.org.cn/man/8/ceph-fuse/
在一台新的客户端或还原快照,然后安装ceph-fuse
[root@ceph- client2 ~]# yum install epel-release -y
[root@ceph-client2 ~]# yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm -y
[ceph@ceph-deploy ceph-cluster]$ scp /etc/yum.repos.d/ceph.repo /etc/yum.repos.d/epel* root@172.31.6.111:/etc/yum.repos.d/
root@ceph-client2 ~]# yum install ceph-fuse ceph-common -y
7.10.2 ceph-fuse 挂载
#同步认证及配置文件:
[ceph@ceph-deploy ceph-cluster]$ scp ceph.conf ceph.client.yanyan.keyring root@172.31 .6.111:/etc/ceph/
root@172.31.6.111's password:
#通过ceph-fuse挂载ceph
[root@ceph-client2 ~]# mkdir /data
[root@ceph-client2 ~]# ceph-fuse --name client.yanyan -m 172.31.6.104:6789,172.31.6.105:6789,172.31.6.106:6789 /data
ceph-fuse[1628]: starting ceph client
2021-06-08 10:51:24.332 7f5a3898ec00 -1 init, newargv = 0x556a48c77da0 newargc=7
ceph-fuse[1628]: starting fuse
#开机挂载,指定用户会自动根据用户名称加载授权文件及配置文件ceph.conf
root@ceph-cient2 ~]# vim /etc/fstab
none /data fuse.ceph
ceph.id=yanyan,ceph.conf=/etc/ceph/ceph.conf,_netdev,defaults 0 0
[root@ceph-client2 ~]# umount /data
[root@ceph-client2 ~]# mount -a
ceph-fuse[1760]: starting ceph client
2021-06-08 10:56:57.602 7f24d91b9c00 -1 init, newargv = 0x55999f6cda40 newargc=9
ceph-fuse[1 7601. startina fuse
7.11 ceph mds高可用
基于多mds服务器,在业务高并发时频繁读写元数据的场景。
Ceph mds(etadata service)作为ceph的访问入口,需要实现高性能及数据备份,假设启动4个MDS进程,设置2个Rank.这时候有2个MDS进�程会分配给两个Rank,还剩下2个MDS进程分别作为另外个的备份。
通过参数指定那主的备是谁
设置每个Rank的备份MDS,也就是如果此Rank当前的MDS出现问题马上切换到另个MDS,设置备份的方法有很多,常用选项如下。mds_standby_replay: 值为true或false, true 表示开启replay 模式,这种模式下主MDS内的数量将实时与从MDS同步,如果主宕机,从可以快速的切换,如果为false只有宕机的时候才去同步数据,这样会有一段时间的中断.mds_standby_for_name:设置当前MDS进程只用于备份于指定名称的MDS.mds_standby_for_rank: 设置当前MDS进程只用于备份于哪个Rank,通常为Rank编号
另外在存在之个CephFS文件系统中,还可以使用mds_standby_for fscid 参数来为指定不同的文件系统。mds_standby_for fscid: 指定CephFS文件系统ID,需要联合mds_standby_for_rank生效,如果设置mds_standby_for_rank, 那么就是用于指定文件系统的指定Rank,如果没有设置,就是指定文件系统的所有Rank。
7.11.1 当前mds服务器状态
[ceph@ceph-deploy ceph-cluster]$ ceph mds stat
mycephfs-1/1/1 up {0=ceph-mgr1=up:active}
7.11.2 添加MDS服务器
将ceph-mgr2和ceph-mon2和ceph-mon3作为mds服务角色添加至ceph集群.
最后实现两主两备的mds高可用和高性能结构。
#mds服务器安装ceph-mds服务
[root@ceph-mgr2 ~]# yum install ceph-mds -y
[root@ceph-mon2 ~]# yum install ceph-mds -y
[root@ceph-mon3 ~]# yum install ceph-mds -y
#添加mds服务器
[ceph@ceph-deploy ceph-cluster]$ ceph-deploy mds create ceph-mgr2
[ceph@ceph-deploy ceph-cluster]$ ceph-deploy mds create ceph-mon2
[ceph@ceph-deploy ceph-cluster]$ ceph-deploy mds create ceph-mon3
#验证mds服务器当前状态:
[ceph@ceph-deploy ceph-cluster]$ ceph mds stat
mycephfs-1/1/1 up {0=ceph-mgr1 =up:active}, 3 up:standby
7.11.3 验证ceph集群当前状态
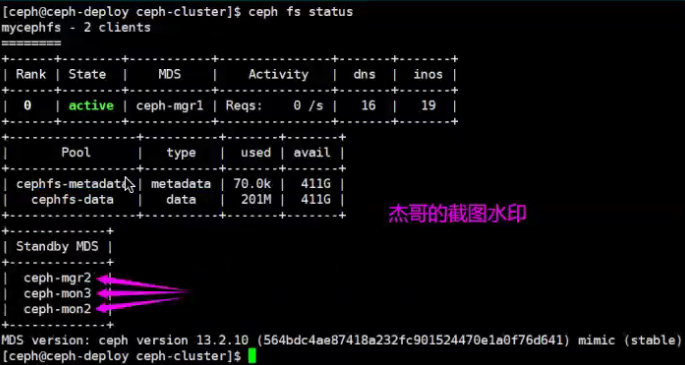
当前处于激活状态的mds服务器有一台,处于备份状态的mds服务器有三台.
[ceph@ceph-deploy ceph-cluster]$ ceph fs status
7.11.4 当前的文件系统状态
[ceph@ceph-deploy ceph-cluster]$ ceph fs get mycephfs
Filesystem 'mycephfs' (1)
fs_name mycephfs
epoch 4
flags
12
created 2021-06-01 17:09:25.850256
modified 2021-06-0117:09:26.854640
tableserver 0
root 0
session_timeout 60
7.11.5 设置处于激活状态的mds的数量
目前有四个mds服务器,但是有一个主三个备,可以优化一 下部署架构,设置为为两主两备
[ceph@ceph-deploy ceph-cluster]$ cepn fs set mycephfs max_mds 2
#设置同时活跃的主mds最大值为2
cephaceph-dep loy :~/ ceph-c luster$ ceph fs status
mycephfs - 1 clients
========
RANK STATE MDS ACTIVITY DNS INOS DIRS CAPS
0 active ceph-mgr1 Reqs: 0 /s 32 19 12 7
1 active ceph-mon2 Reqs: 0 /s 10 13 11 0
POOL TYPE USED AVAIL
cephfs-metadata metadata 1347k 630G
cephfs-data data 849M 630G
STANDBY MDS
ceph-mon1
ceph-mon3
MDS version: ceph version 16.2.5 ( 0883bdea7337b95e4b611c768c0279868462204a) pacific (stable)
7.11.6 MDS高可用优化
目前的状态是ceph-mgr1和ceph-mon2分别是active 状态,ceph-mon3 和ceph-mgr2分别处于standby状态。
现在可以将ceph-mgr2设置为ceph-mgr1的standby,将ceph-mon3设置为ceph-mon2的standby,以实现每个主都有一个固定备份角色的结构,则修改配置文件如下:
[ceph@ceph-deploy ceph-cluster]$ vim ceph.conf
[global]
fsid = 23b0f9f2-8db3-477f-99a7-35a90eaf3dab
public_ network = 172.31.0.0/21
cluster_ network = 192.168.0.0/21
mon_ initial members = ceph-mon1
monhost= 172.31.6.104
auth_ cluster_ required = cephx
auth service_ required = cephx
auth_ client required = cephx
mon clock drift allowed = 2
mon clock drift warn backoff = 30
[mds.ceph-mgr2] #指定mgr的配置
#mds_standby_for_fscid = mycephfs
mds_standby_for_name = ceph-mgr1 #指定主是谁
mds_standby_replay = true
[mds_ceph-mon3] #指定mon3的配置
mds_standby_for name = ceph-mon2 #指定主是谁
mds_standby_replay = true
7.11.7 分发配置文件并重启mds服务
#分发配置文件保证各mds服务重启有效
$ ceph-deploy --overwrite-conf config push ceph-mon3
$ ceph-deploy --overwrite-conf config push ceph-mon2
$ ceph-deploy --overwrite-conf config push ceph-mgr1
$ ceph-deploy --overwrite-conf config push ceph-mgr2
root@ceph-mon2 ~]# systemctl restart ceph-mds@ceph-mon2 .service
root@ceph-mon3 ~]# systemctl restart ceph-mds@ceph-mon3.service
root@ceph-mgr2 ~]# systemctl restart ceph-mds@ceph-mgr2.service
root@ceph-mgr1 ~]# systemctl restart ceph-mds@ceph-mgr1.service
7.11.8 ceph集群mds高可用状态
ceph fs status
7.12 通过ganesha将cephfs导出为NFS
通过ganesha将cephfs通过NFS协议共享使用。
https://www.server-world.info/en/note?os=Ubuntu_20.04&p=ceph15&f=8
把Ceph Fs 中转成NFS协议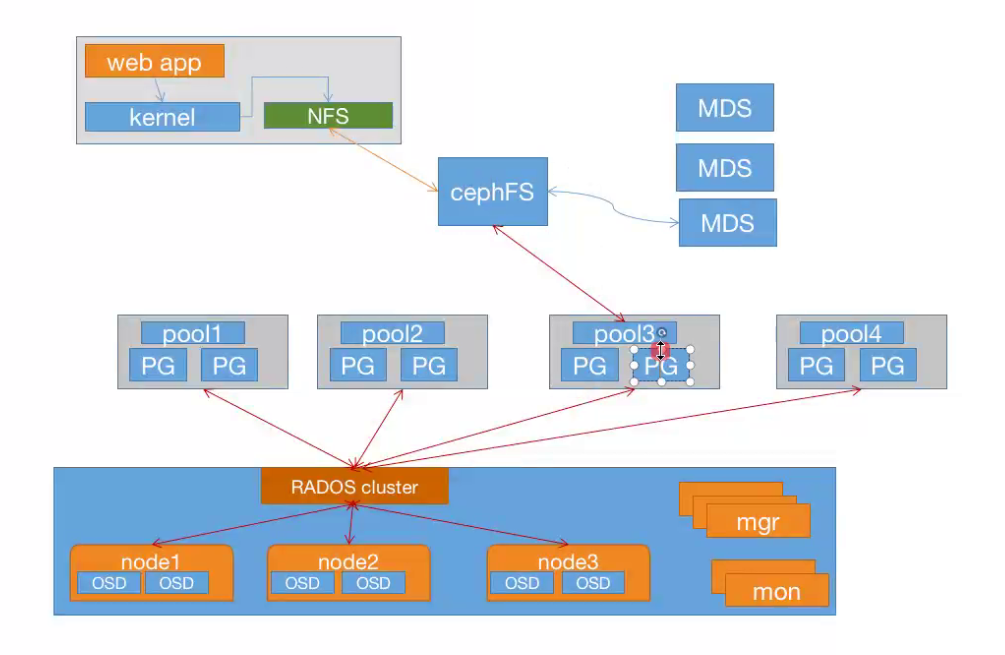
7.12.1 服务端配置
root@ceph-mgr1:~# apt install nfs-ganesha-ceph
root@ceph-mgr1:~# cd /etc/ganesha/
root@ceph-mgr1:/etc/ganesha# cat ganesha.conf
# create new
NFS_CORE_PARAM {
# disable NLM
Enable_ NLM = false;
# disable RQUOTA (not suported on CephFS)
Enable_ RQUOTA = false;
# NFS protocol
Protocols = 4;
}
EXPORT_DEFAULTS {
# default access mode
Access_Type = RW;
}
EXPORT {
# uniq ID
Export_ld = 1;
# mount path of CephFS
Path = "/";
FSAL {
name = CEPH;
# hostname or IP address of this Node
hostname="172.31.6.104";
}
# setting for root Squash
Squash="No_root_squash";
# NFSv4 Pseudo path
Pseudo= */magedu";
# allowed security options
SecType = "sys";
}
LOG {
# default log level
Default_ _Log_ Level = WARN;
}
root@ceph-mgr1:/etc/ganesha# systemctl restart nfs-ganesha
7.12.2 客户端挂载测试
root@ceph- client3-ubuntu1804:~# mount -t nfs 172.31.6.104:/magedu /data
验证挂载:
df -TH
#客户端测试写人数据:
root@ceph-client3-ubuntu1804:~# echo "ganesha v11111111" >> /data/magedu/data/magedu.txt