13.HPA自动伸缩pod数量
1.HPA简介
HPA(Horizontal Pod Autoscaler)和 VPA(Vertical Pod Autoscaler)是 Kubernetes 中用于自动调整容器资源的两种不同方法。
HPA 用于水平自动缩放,可以根据 Pod 的负载情况自动调整 Pod 的副本数量。在业务高峰期,HPA 可以自动扩展 Pod 副本以满足增加的业务请求,而在低峰期则可以自动缩减 Pod 的副本数量,以节约资源。
VPA 则用于垂直自动缩放,它关注的是单个 Pod 的资源利用率,可以根据 Pod 的资源需求动态调整 Pod 的资源限制,例如 CPU 和内存。VPA 可以调整 Pod 的资源请求和限制,以更好地适应 Pod 实际的需求,但不能像 HPA 那样增加或减少 Pod 的副本数量。
HPA隶属于autoscaling API群组目前主要有v1和v2两个版本:
| 版本 | 描述 |
|---|---|
| autoscaling/v1 | 只支持基于CPU指标的缩放 |
| autoscaling/v2 | 支持基于Resource Metrics(资源指标,例如Pod 的CPU和内存)、Custom Metrics(自定义指标)和External Metrics(额外指标)的缩放 |
2.部署 metrics Server
HPA需要通过Metrics Server来获取Pod的资源利用率,所以需要先部署Metrics Server。
Metrics Server是Kubernetes 集群核心监控数据的聚合器,它负责从kubelet收集资源指标,然后对这些指标监控数据进行聚合,并通过Metrics API将它们暴露在Kubernetes apiserver中,供水平Pod Autoscaler和垂直Pod Autoscaler使用。也可以通过kubectl top node/pod查看指标数据。
2.1 准备镜像
#从代理服务器上下载好镜像
root@harbor01[13:32:22]/proxy-images #:docker tag k8s.gcr.io/metrics-server/metrics-server:v0.6.2 harbor.ceamg.com/k8s-base/metrics-server:v0.6.2
root@harbor01[13:32:59]/proxy-images #:docker push harbor.ceamg.com/k8s-base/metrics-server:v0.6.2
The push refers to repository [harbor.ceamg.com/k8s-base/metrics-server]
dc5ecd167a15: Pushed
9fce6bd02a21: Pushed
v0.6.2: digest: sha256:0542aeb0025f6dd4f75e100ca14d7abdbe0725c75783d13c35e82d391f4735bc size: 739
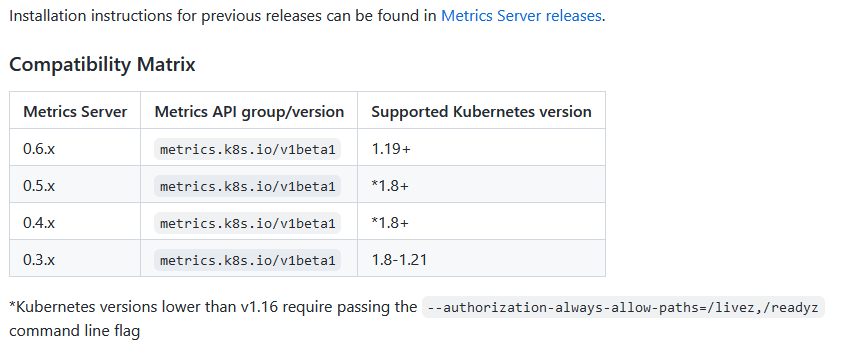
下载yaml文件 Metrics Server releases.
V6.0.2 https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.2/components.yaml
修改文件中的镜像地址为私有仓库
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: harbor.ceamg.com/k8s-base/metrics-server:v0.6.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
2.2 创建pod
创建之后查看Pod状态:
root@master01[13:41:51]~/metrics #:kubectl apply -f metrics-v6.0.2.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
root@master01[13:41:55]~/metrics #:kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-5c8bb696bb-hf2cp 1/1 Running 1 (42d ago) 43d
calico-node-4ntd2 1/1 Running 0 42d
calico-node-dwnq5 1/1 Running 0 42d
calico-node-nskdq 1/1 Running 0 42d
calico-node-slx2b 1/1 Running 0 42d
coredns-6c496b89f6-hd8vf 1/1 Running 0 42d
metrics-server-5cd7bd59b4-tzx2b 1/1 Running 0 2m24s
2.3 验证资源指标
验证metrics-server是否工作
root@master01[13:44:57]~/metrics #:kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
10.1.0.30 229m 2% 3731Mi 51%
10.1.0.31 323m 4% 3481Mi 47%
10.1.0.32 417m 5% 4713Mi 64%
10.1.0.33 331m 4% 5453Mi 75%
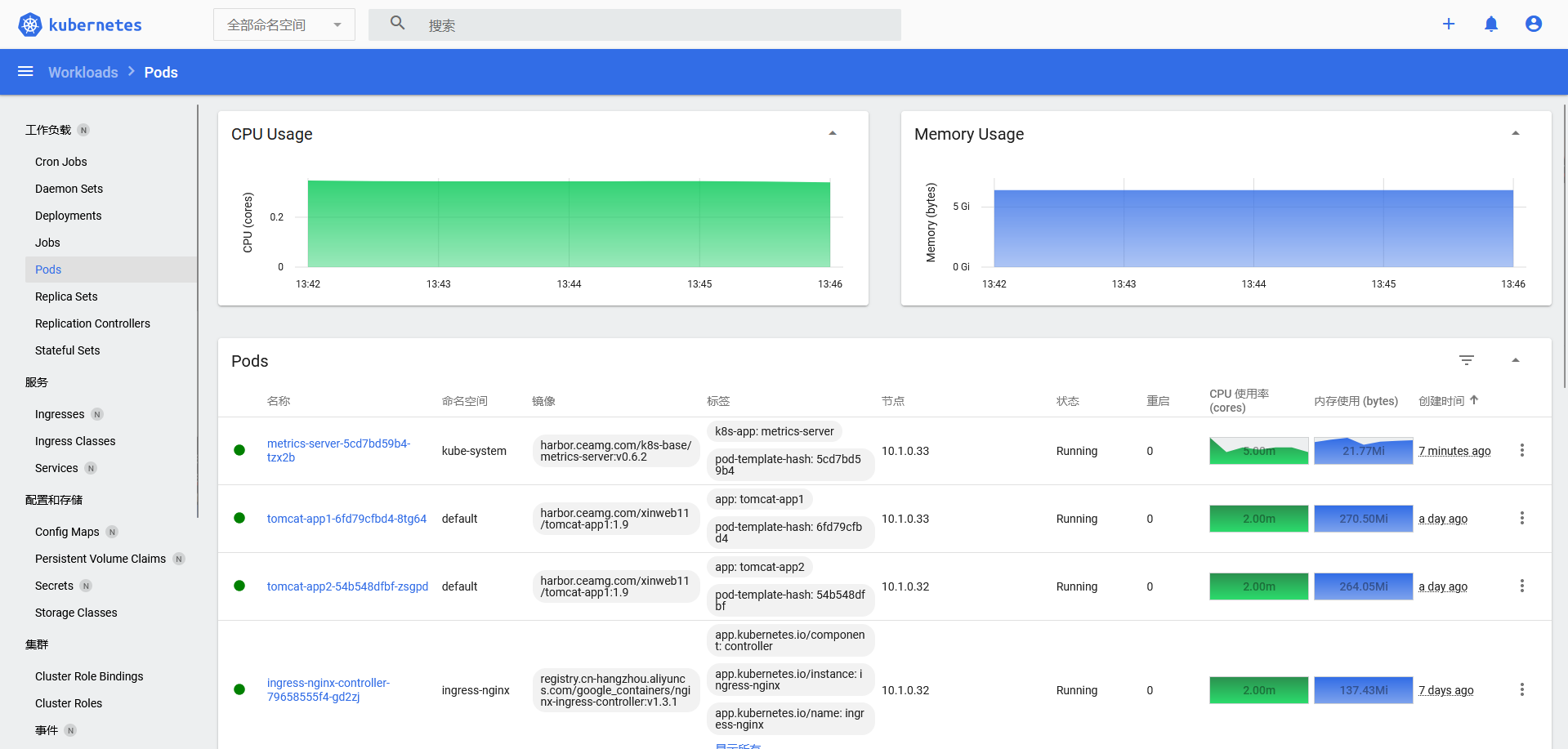
可以获取node和pod的资源指标��就表示metrics-server可以正常工作
3. HPA配置参数
HPA控制器有一些重要配置参数,用于控制Pod缩放的行为,这些参数都可以在kube-controller的启动参数中配置:
--horizontal-pod-autoscaler-sync-period:这个参数定义了 HPA 查询 Pod 资源利用率的时间间隔,默认为 15 秒,也就是 HPA 每隔 15 秒查询一次 Pod 的资源利用率来进行调整。
--horizontal-pod-autoscaler-downscale-stabilization:这个参数指定了两次缩容操作之间的最小间隔周期,默认为 5 分钟。这意味着如果在该间隔内已经进行了一次缩容操作,HPA 将不会在此期间内继续执行缩容操作,以避免频繁地调整 Pod 的副本数量。
--horizontal-pod-autoscaler-cpu-initialization-period:该参数定义了初始化延迟时间,在此期间内 Pod 的 CPU 指标将不会被纳入考虑。默认为 5 分钟,意味着在刚启动 HPA 或者 Pod 初始化的时候,HPA 将不会立即根据 CPU 利用率进行缩放操作。
--horizontal-pod-autoscaler-initial-readiness-delay:这个参数用于设置 Pod 初始化时间,在此期间内的 Pod 被认为未就绪不会被采集数据。默认为 30 秒,即 Pod 初始化时,在 30 秒内被认为未就绪,不会被纳入资源利用率的计算。
--horizontal-pod-autoscaler-tolerance:这个参数定义了 HPA 控制器能容忍的数据差异(浮点数,默认为 0.1)。即当前指标与阈值的差异要在 0.1 之内,例如,如果阈值设置的是 CPU 利率为 50%,如果当前 CPU 利用率为 80%,那么 80/50=1.6,超过了 1.1(1+0.1),就会触发扩容;如果当前 CPU 利用率为 40%,那么 40/50=0.8,低于 0.9(1-0.1),就会触发缩容。即大于 1.1 扩容,小于 0.9 缩容。
3.1 HPA示例
下面使用HAP v1版本通过CPU指标实现Pod自动扩缩容。
3.1.1 自动缩容示例
先部署一个5副本的nginx deployment,再通过HPA实现缩容:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deploy
labels:
app: nginx
spec:
replicas: 5
selector:
matchExpressions:
- {key: "app", operator: In, values: ["nginx"]}
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: harbor.ceamg.com/pub-images/nginx-base:1.22.1
ports:
- name: http
containerPort: 80
resources: #如果要通过hpa实现pod的自动扩缩容,在必须对Pod设置资源限制,否则pod不会被hpa统计
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1
memory: 1Gi
root@master01[13:56:32]~/metrics/test #:kubectl get pod
NAME READY STATUS RESTARTS AGE
emptydirtest 1/1 Running 4 (6h40m ago) 16d
net-test2 1/1 Running 10 (31h ago) 42d
net-test3 1/1 Running 10 (31h ago) 42d
net-test4 1/1 Running 10 (31h ago) 42d
nginx-deploy-74d4966b8c-2qs8m 1/1 Running 0 33s
nginx-deploy-74d4966b8c-7fcpl 1/1 Running 0 33s
nginx-deploy-74d4966b8c-pn6nx 1/1 Running 0 33s
nginx-deploy-74d4966b8c-qtdps 1/1 Running 0 33s
nginx-deploy-74d4966b8c-rhgm4 1/1 Running 0 33s
hpa部署文件如下,在hpa中定义了Pod cpu利用率阈值为80%,最小副本数为3,最大副本数为10:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pod-autoscaler-demo
spec:
minReplicas: 3 #最小副本数
maxReplicas: 10 #最大副本数
scaleTargetRef: #hpa监控的资源对象
apiVersion: apps/v1
kind: Deployment
name: nginx-deploy
targetCPUUtilizationPercentage: 80 #cpu利用率阈值
创建完成后,查看hpa资源:
root@master01[15:23:46]~/metrics/test #:kubectl get hpa -o wide
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
pod-autoscaler-demo Deployment/nginx-deploy 0%/80% 3 10 5 21s
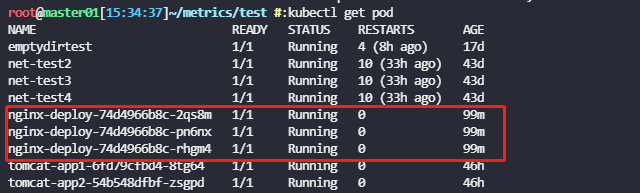
因为之前创建的nginx pod访问量较低,cpul利用率肯定不超过80%,所以等待一段时间就会触发缩容 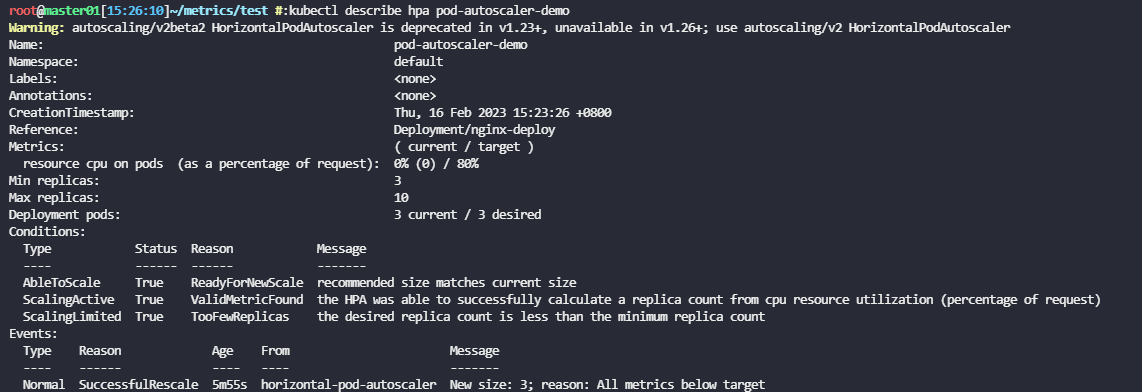
因为在hpa中定义的最小副本数为3,所以缩容到3个Pod就不会缩容了
3.1.2 自动扩容示例
使用stress-ng镜像部署3个pod来测试自动扩容,stress-ng是一个压测工具
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress-ng-deploy
labels:
app: stress-ng
spec:
replicas: 3
selector:
matchExpressions:
- {key: "app", operator: In, values: ["stress-ng"]}
template:
metadata:
labels:
app: stress-ng
spec:
containers:
- name: stress-ng
image: lorel/docker-stress-ng
args: ["--vm", "2", "--vm-bytes", "512M"]
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1
memory: 1Gi
root@master01[16:34:20]~/metrics/test #:kubectl get pod
NAME READY STATUS RESTARTS AGE
stress-ng-deploy-5c9d6db588-dmwh8 1/1 Running 0 30s
stress-ng-deploy-5c9d6db588-mfr7m 1/1 Running 0 30s
stress-ng-deploy-5c9d6db588-vg82w 1/1 Running 0 30s
hpa部署文件如下:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: pod-autoscaler-demo1
spec:
minReplicas: 3
maxReplicas: 10
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: stress-ng-deploy
targetCPUUtilizationPercentage: 80
查看hpa资源: 
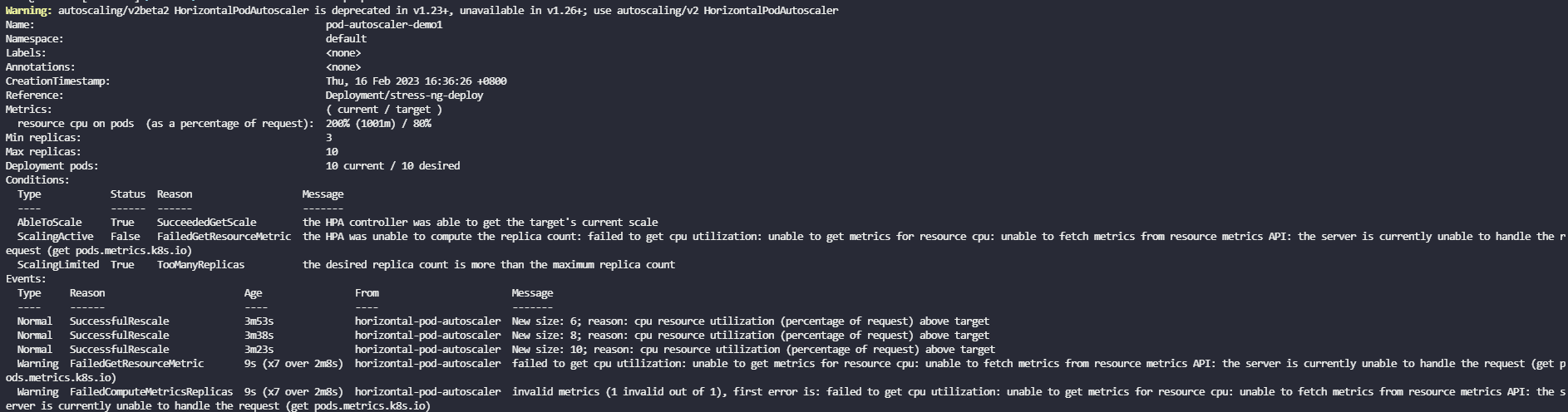 stress-ng会将Pod的cpu利用率打满,所以等待一段时间hpa就会逐步提高pod的副本数,如下图所示,但是在hpa中定义的最大副本数为10,所以最多扩容到10个Pod就不会扩容了
stress-ng会将Pod的cpu利用率打满,所以等待一段时间hpa就会逐步提高pod的副本数,如下图所示,但是在hpa中定义的最大副本数为10,所以最多扩容到10个Pod就不会扩容了 
删除一直处于Terminating 状态的pod
root@master01[16:54:36]~/metrics/test #:kubectl get pod
NAME READY STATUS RESTARTS AGE
emptydirtest 1/1 Terminating 4 (9h ago) 17d
net-test2 1/1 Terminating 10 (34h ago) 43d
net-test3 1/1 Terminating 10 (34h ago) 43d
net-test4 1/1 Running 10 (35h ago) 43d
nginx-deploy-74d4966b8c-2qs8m 1/1 Running 0 3h5m
nginx-deploy-74d4966b8c-k28hh 1/1 Running 0 14m
nginx-deploy-74d4966b8c-pn6nx 1/1 Terminating 0 3h5m
nginx-deploy-74d4966b8c-rhgm4 1/1 Running 0 3h5m
stress-ng-deploy-5c9d6db588-7q4hq 1/1 Terminating 0 24m
stress-ng-deploy-5c9d6db588-dmwh8 1/1 Terminating 0 27m
stress-ng-deploy-5c9d6db588-m952t 1/1 Terminating 0 24m
stress-ng-deploy-5c9d6db588-mwbgd 1/1 Terminating 0 24m
stress-ng-deploy-5c9d6db588-vg82w 1/1 Terminating 0 27m
stress-ng-deploy-5c9d6db588-z8n2r 0/1 Terminating 0 24m
tomcat-app1-6fd79cfbd4-8tg64 1/1 Terminating 0 2d
tomcat-app1-6fd79cfbd4-sts9v 1/1 Running 0 14m
tomcat-app2-54b548dfbf-zsgpd 1/1 Running 0 2d
root@etcd01[17:03:05]~ #:/usr/local/bin/etcdctl get /registry/pods/default/stress --prefix --keys-only
/registry/pods/default/stress-ng-deploy-5c9d6db588-7q4hq
/registry/pods/default/stress-ng-deploy-5c9d6db588-dmwh8
/registry/pods/default/stress-ng-deploy-5c9d6db588-m952t
/registry/pods/default/stress-ng-deploy-5c9d6db588-mwbgd
/registry/pods/default/stress-ng-deploy-5c9d6db588-vg82w
/registry/pods/default/stress-ng-deploy-5c9d6db588-z8n2r
# 删除 namespace下的pod名为pod-to-be-deleted-0
export ETCDCTL_API=3
etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-z8n2r
etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-7q4hq
etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-dmwh8
etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-mwbgd
etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-vg82w
etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-m952t
root@etcd01[17:03:37]~ #:etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-z8n2r
1
root@etcd01[17:04:54]~ #:etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-7q4hq
1
root@etcd01[17:04:54]~ #:etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-dmwh8
1
root@etcd01[17:04:54]~ #:etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-mwbgd
1
root@etcd01[17:04:54]~ #:etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-vg82w
1
root@etcd01[17:04:54]~ #:etcdctl del /registry/pods/default/stress-ng-deploy-5c9d6db588-m952t
1
删除后查看
root@etcd01[17:05:07]~ #:/usr/local/bin/etcdctl get /registry/pods/default/ --prefix --keys-only
/registry/pods/default/emptydirtest
/registry/pods/default/net-test2
/registry/pods/default/net-test3
/registry/pods/default/net-test4
/registry/pods/default/nginx-deploy-74d4966b8c-2qs8m
/registry/pods/default/nginx-deploy-74d4966b8c-k28hh
/registry/pods/default/nginx-deploy-74d4966b8c-pn6nx
/registry/pods/default/nginx-deploy-74d4966b8c-rhgm4
/registry/pods/default/tomcat-app1-6fd79cfbd4-8tg64
/registry/pods/default/tomcat-app1-6fd79cfbd4-sts9v
/registry/pods/default/tomcat-app2-54b548dfbf-zsgpd