8.AlertManager_高级警报管理
Silences 和 Inhibition 是 Alertmanager 中的两个重要功能,它们旨在解决监控系统中的常见问题并提供更好的警报管理机制。这些功能的主要目的是降低警报干扰、减少误报、提供细粒度控制以及避免警报风暴。
Inhibition
在 Prometheus 中,Inhibition 是一种与 Silences 类似但功能更强大的机制。它允许用户根据特定的警报规则来阻止其他警报的触发,从而更细粒度地控制警报流量和处理行为。
- Inhibitor 规则:Inhibition 是通过定义 Inhibitor 规则来实现的。这些规则指定了当某个警报触发时,应该阻止哪些其他警报的触发。Inhibitor 规则通常基于警报的标签和值进行匹配。
- 动态生效:与 Silences 不同,Inhibition 规则是动态生效的,这意味着它们在被定义和修改后会立即生效,而不需要等待特定的时间段。
- 匹配规则:类似于 Silences,Inhibition 也使用匹配规则来确定哪些警报应该被阻止。这些规则可以是精确匹配,也可以是正则表达式匹配,使得用户可以根据需要对警报进行更精细的控制。
- 警报链:当某个警报触发时,Prometheus 将会遍历所有定义的 Inhibitor 规则,检查是否有匹配的规则。如果找到匹配的规则,那么被规则阻止的警报将不会被触发。
- 灵活性:Inhibition 提供了比 Silences 更灵活和强大的警报管理机制。通过阻止特定警报触发其他警报,用户可以更加精细地控制警报的行为,以适应复杂的监控场景和需求。
Silences
是用来处理警报的一种机制,它允许用户在特定时间段内暂时性地禁用或忽略某些警报,以减少干扰或者在必要时进行维护操作。
基于 Matchers 配置:Silences 使用 matchers 来指定警报的标签和值,类似于 Prometheus 中的查询语句。这些 matchers 允许用户精确地定义需要被静默的警报。
类似路由树的工作方式:当警报触发时,Prometheus 将会检查当前处于活动状态的 Silences。这些 Silences 的配置类似于路由树,系统会按照匹配规则逐级检查,以确定是否有与触发的警报匹配的 Silence。
匹配规则:Silences 可以通过匹配规则来确定是否应该忽略特定的警报。这些规则可以是精确匹配,也可以是正则表达式匹配,使得用户可以根据需要对警报进行更灵活的管理。
时间限制:Silences 是临时性的,用户可以为其设置一个特定的时间段,在这个时间段内触发的警报将被静默。一旦这个时间段过去,Silences 将自动失效,警报将会重新生效。
减少干扰:通过使用 Silences,用户可以有针对性地忽略一些不重要或者在特定时间段内不需要处理的警报,从而减少了干扰和误报的数量。
由于全局配置中我们配置的 repeat_interval: 1h,所以正常来说,上面的测试报警如果一直满足报警条件(内存使用率大于 20%)的话,那么每 1 小时我们就可以收到一条报警邮件。
一条告警产生后,还要经过 Alertmanager 的分组、抑制处理、静默处理、去重处理和降噪处理最后再发送给接收者。这个过程中可能会因为各种原因会导致告警产生了却最终没有进行通知,可以通过下图了解整个告警的生命周期: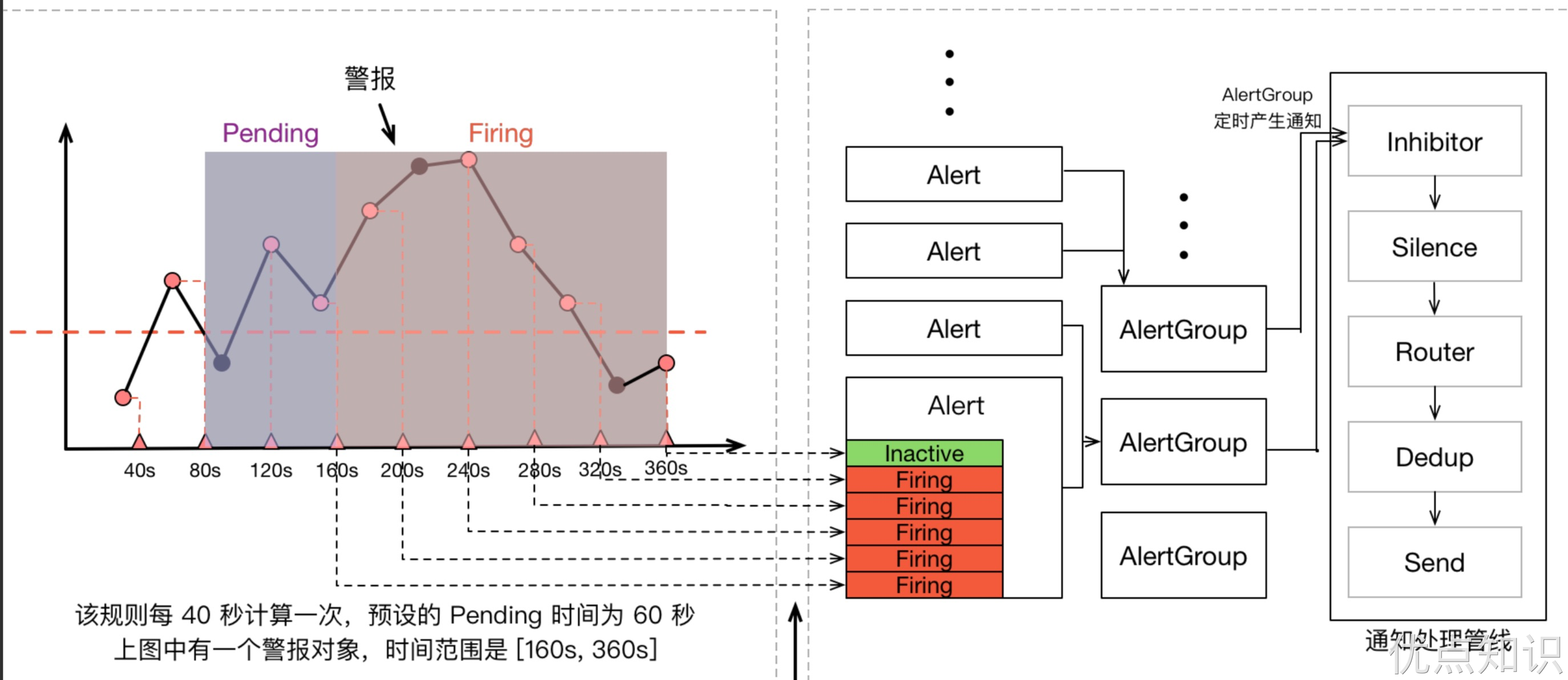
报警过滤
有的时候可能报警通知太过频繁,或者在收到报警通知后就去开始处理问题了,这个期间可能报警还在频繁发送,这个时候我们可以去对报警进行静默设置。
静默通知 Silences
在 Alertmanager 的后台页面中提供了静默操作的入口。
可以点击右上面的 New Silence 按钮新建一个静默通知: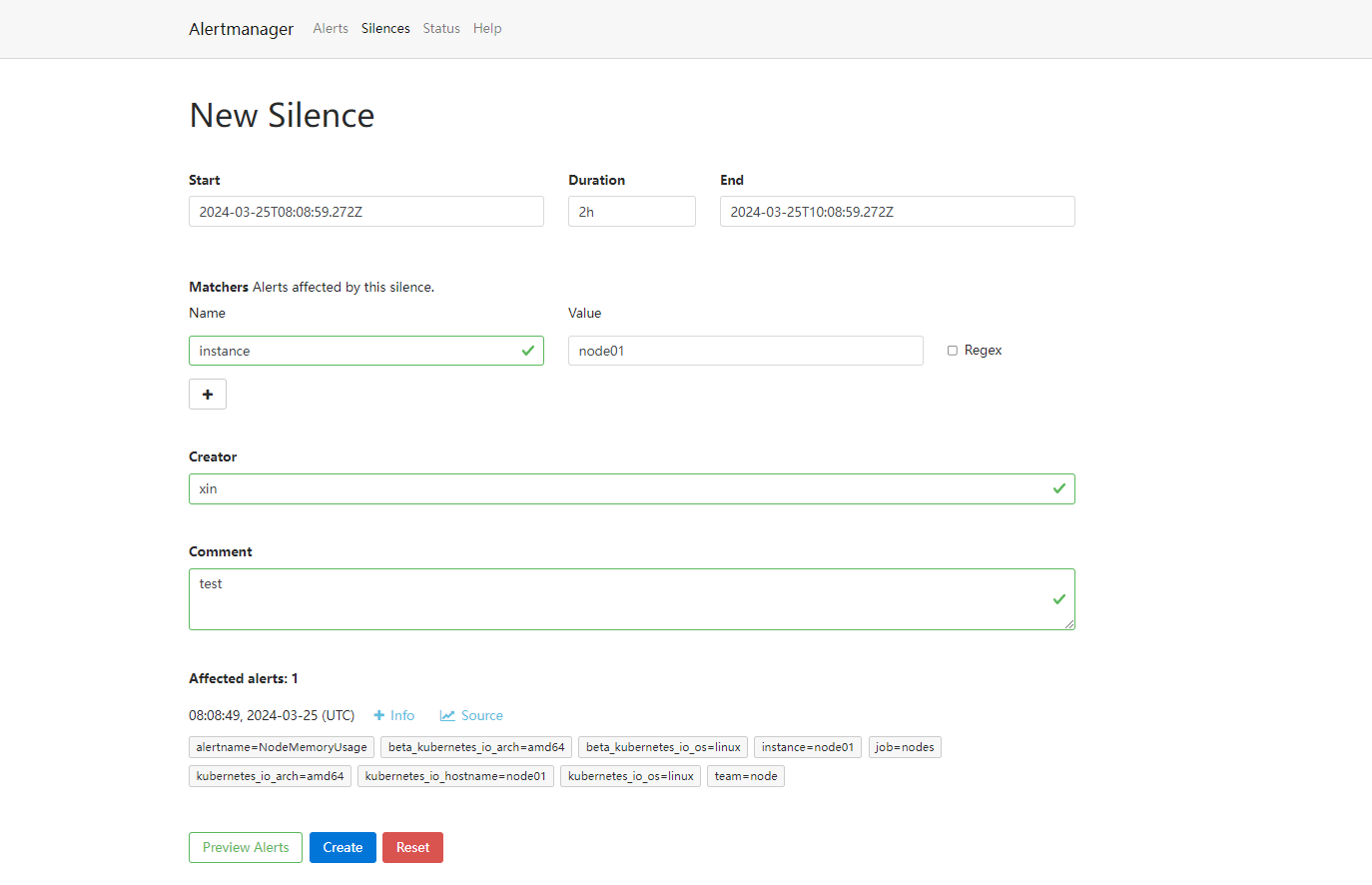
我们可以选择此次静默的开始时间、结束时间,最重要的是下面的 Matchers 部分,用来匹配哪些报警适用于当前的静默,比如这里我们设置 instance=node2 的标签,则表示具有这个标签的报警在 2 小时内都不会触发报警,点击下面的 Create 按钮即可创建: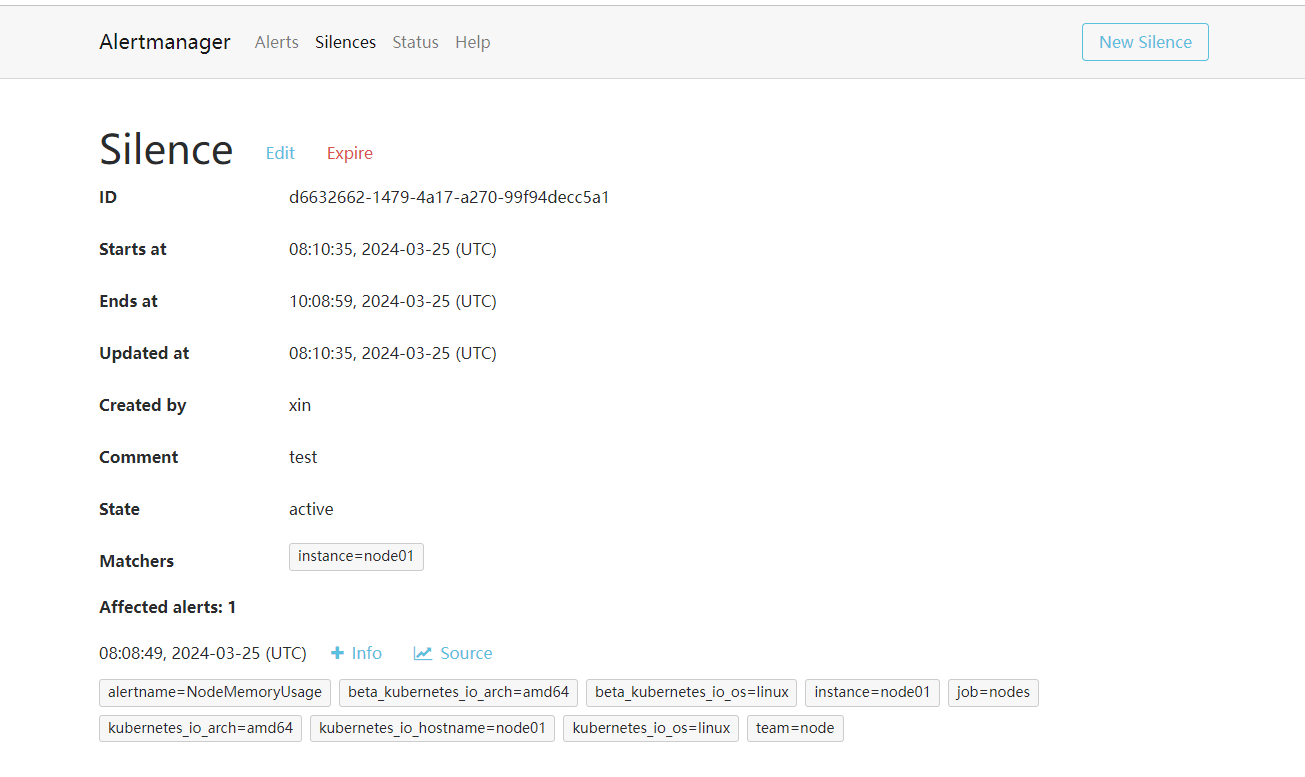
创建完成后还可以对该配置进行编辑或者让其过期等操作。此时在静默列表也可以看到创建的静默状态。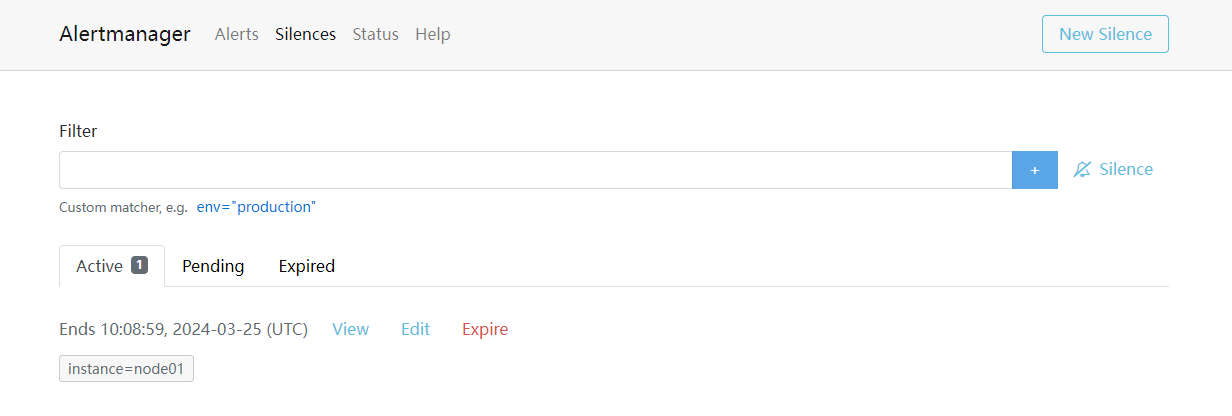
抑制通知 Inhibition
除了上面的静默机制之外,Alertmanager 还提供了抑制机制来控制告警通知的行为。抑制是指当某次告警发出后,可以停止重复发送由此告警引发的其他告警的机制,比如现在有一台服务器宕机了,上面跑了很多服务都设置了告警,那么肯定会收到大量无用的告警信息,这个时候抑制就非常有用了,可以有效的防止告警风暴。
要使用抑制规则,需要在 Alertmanager 配置文件中的inhibit_rules属性下面进行定义,每一条抑制规则的具体配置如下:
target_match:
[ <labelname>: <labelvalue>, ... ]
target_match_re:
[ <labelname>: <regex>, ... ]
source_match:
[ <labelname>: <labelvalue>, ... ]
source_match_re:
[ <labelname>: <regex>, ... ]
equal: '[' <labelname>, ... ']'
目标匹配规则(target_match 和 target_match_re)用于指定要匹配的目标标签和值。例如,可以使用这些规则来指定应该将警报发送到哪些接收者。当系统接收到新的警报时,会应用源匹配规则(source_match 或 source_match_re)来确定是否应该考虑对新产生的告警进行抑制。这些规则通常用于过滤出特定来源或类型的警报。如果新的告警与已发送的告警中的 equal 定义的标签完全相同,则会启动抑制机制。
target_match 用于精确匹配,而 target_match_re 则允许使用正则表达式进行模糊匹配,source_match_re 与 target_match_re类似,它也是用于匹配源标签和值的规则,允许使用正则表达式进行模糊匹配。
例如当集群中的某一个主机节点异常宕机导致告警 NodeDown 被触发,同时在告警规则中定义了告警级别为
severity=critical,由于主机异常宕机,则该主机上部署的所有服务会不可用并触发报警,根据抑制规则的定义,如果有新的告警级别为severity=critical,并且告警中标签 instance 的值与 NodeDown 告警的相同,则说明新的告警是由 NodeDown 导致的,则启动抑制机制停止向接收器发送通知。
- source_match:
alertname: NodeDown
severity: critical
target_match:
severity: critical
equal:
- instance
比如现在我们如下所示的两个报警规则 NodeMemoryUsage 与 NodeLoad:
groups:
- name: test-node-mem
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 30
for: 2m
labels:
team: node
severity: critical
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
description: "{{$labels.instance}}: Memory usage is above 30% (current value is: {{ $value }})"
- name: test-node-load
rules:
- alert: NodeLoad
expr: node_load5 < 1
for: 2m
labels:
team: node
severity: normal
annotations:
summary: "{{ $labels.instance }}: Low node load deteched"
description: "{{ $labels.instance }}: node load is below 1 (current value is: {{ $value }})"
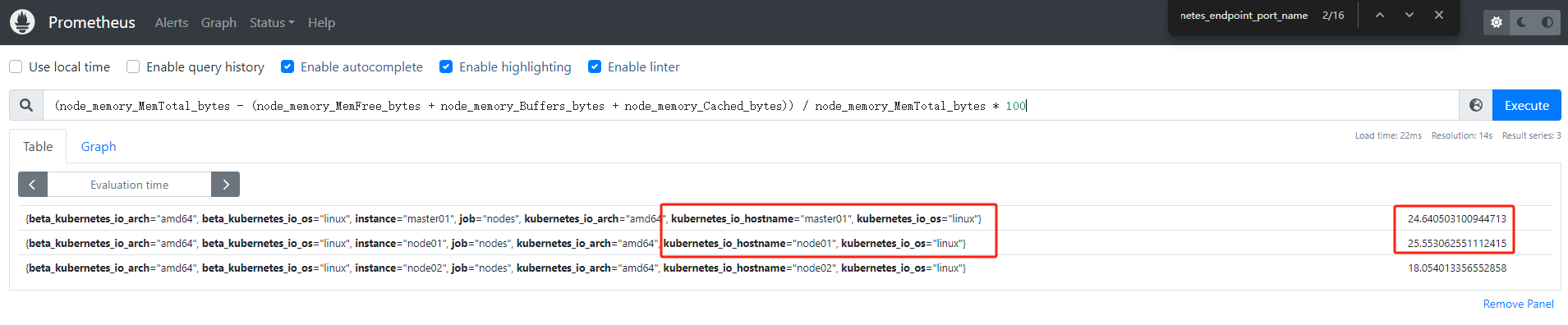
当前我们系统里面普通(severity: normal)的告警有三条,node1、node2 和 master1 三个节点,因为master1 和 node1 两个节点内存使用率超过20%所以报警只有两条,: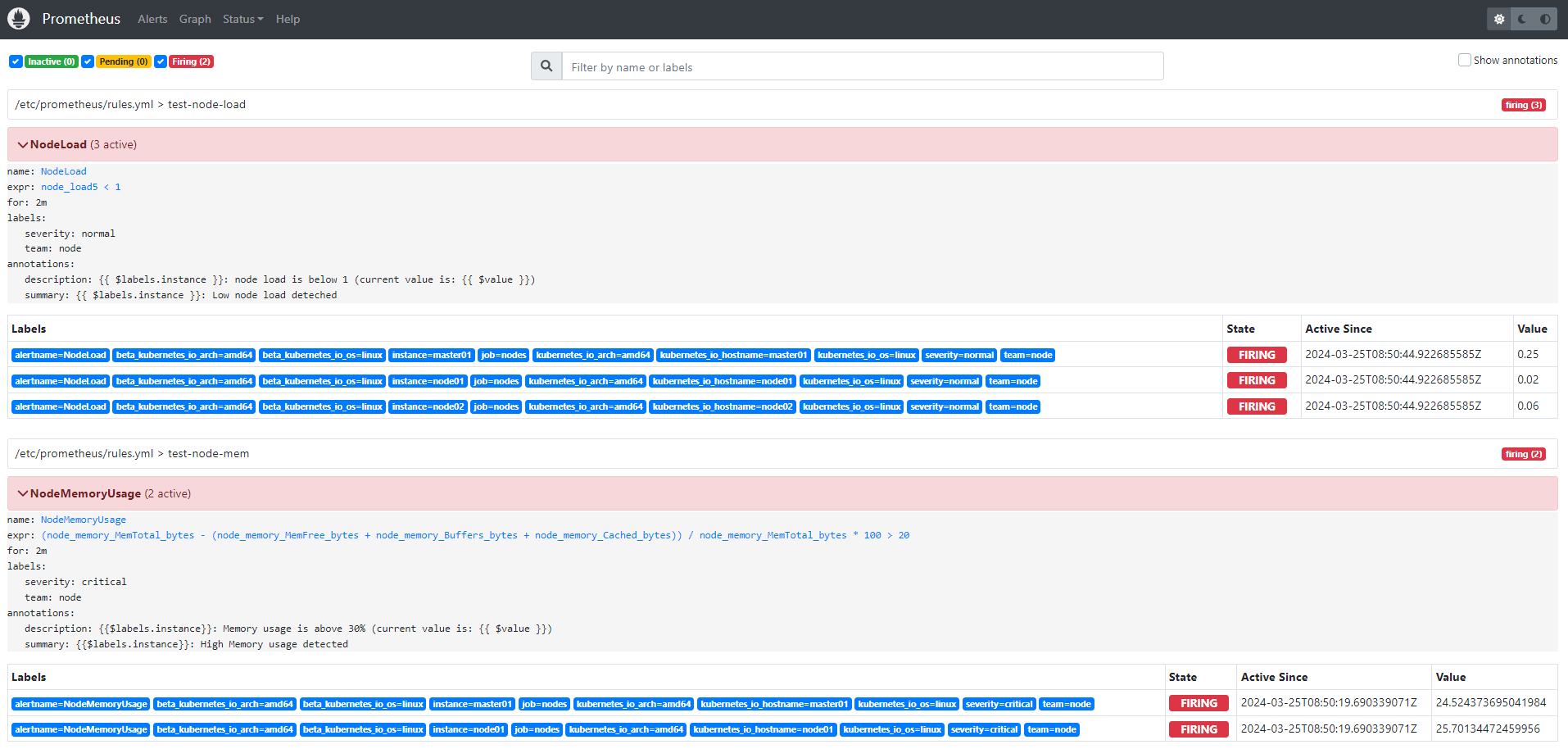
现在我们假设来配置一个抑制规则,如果 NodeMemoryUsage 报警触发,则抑制 NodeLoad 指标规则引起的报警,我们这里就会抑制 master1 和 node2 节点的告警,只会剩下 node1 节点的普通告警。
在 Alertmanager 配置文件中添加如下所示的抑制规则:
inhibit_rules:
- source_match:
alertname: NodeMemoryUsage
severity: critical
target_match:
severity: normal
equal:
- instance
更新配置后,最好重建下 Alertmanager,这样可以再次触发下报警,可以看到只能收到 node2 节点的 NodeLoad 报警了,另外两个节点的报警被抑制了: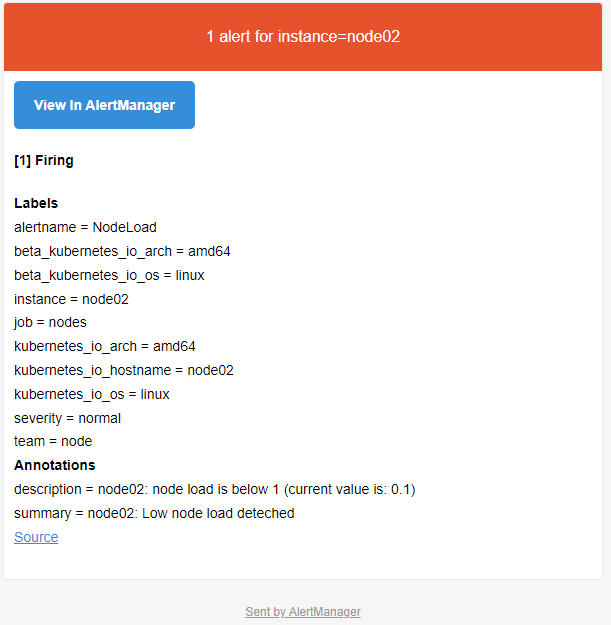
这就是 Alertmanager 抑制的使用方式。
报警接收器
Alertmanager 支持很多内置的报警接收器,如 email、slack、企业微信、webhook 等,上面的测试我们使用的 email 来接收报警。
通知模板
告警通知使用的是默认模版�,因为它已经编译到二进制包了,所以我们不需要额外配置。
如果我们想自定义模版,这又该如何配置呢?
Alertmanager 默认使用的通知模板可以从 https://github.com/prometheus/alertmanager/blob/master/template/default.tmpl 获取,Alertmanager 的通知模板是基于 Golang 的模板系统,当然也支持用户自定义和使用自己的模板。
第一种方式是基于模板字符串,直接在 Alertmanager 的配置文件中使用模板字符串,如下所示:
receivers:
- name: "slack-notifications"
slack_configs:
- channel: "#alerts"
text: "https://internal.myorg.net/wiki/alerts/{{ .GroupLabels.app }}/{{ .GroupLabels.alertname }}"
直接在配置文件中可以使用一些模板字符串,比如获取 {{ .GroupLabels }} 下面的一些属性。
官方邮件模板
另外一种方法就是直接修改官方默认的模板,此外也可以自定义可复用的模板文件,比如针对 email 的模板,我们可以创建一个名为 template_email.tmpl 的自定义模板文件,如下所示:
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: monitor
data:
config.yml: |-
global: # 全局配置
......
route: # 路由
......
templates: # 增加 templates 配置,指定模板文件
- '/etc/alertmanager/template_email.tmpl'
receivers: # 接收器
- name: 'email'
email_configs:
- to: '517554016@qq.com'
send_resolved: true
html: '{{ template "email.html" . }}' # 此处通过 html 指定模板文件中定义的 email.html 模板
# 下面定义 email.html 必须和上面指定的一致,注释不能写进模板文件中
template_email.tmpl: |-
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
@报警<br>
<strong>实例:</strong> {{ .Labels.instance }}<br>
<strong>概述:</strong> {{ .Annotations.summary }}<br>
<strong>详情:</strong> {{ .Annotations.description }}<br>
<strong>时间:</strong> {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}<br>
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}<br>
@恢复<br>
<strong>实例:</strong> {{ .Labels.instance }}<br>
<strong>信息:</strong> {{ .Annotations.summary }}<br>
<strong>恢复:</strong> {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
在 Alertmanager 配置中通过 templates 属性来指定我们自定义的模板路径,这里我们定义的 template_email.tmpl 模板会通过 Configmap 挂载到 /etc/alertmanager 路径下,模板中通过 {{ define "email.html" }} 定义了一个名为 email.html 的命名模板,然�后在 email 的接收器中通过 email_configs.html 来指定定义的命名模板即可。
更新上面 Alertmanager 的配置对象,重启 Alertmanager 服务,然后等待告警发出,即可看到我们如下所示自定义的模板信息: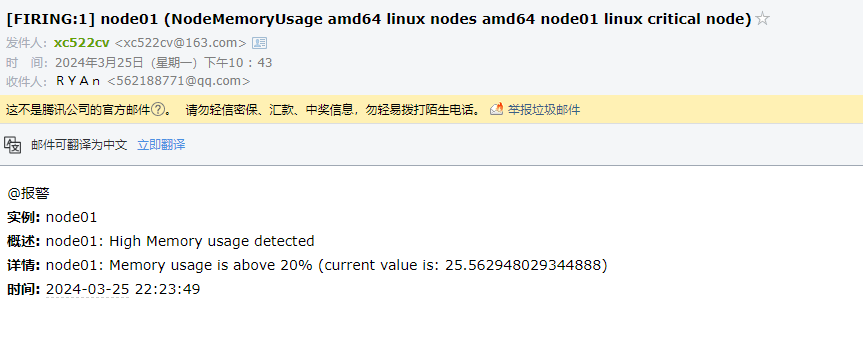
WebHook 接收器
上面我们配置的是 AlertManager 自带的邮件报警模板,我们也说了 AlertManager 支持很多中报警接收器,比如 slack、微信之类的,其中最为灵活的方式当然是使用 webhook 了,我们可以定义一个 webhook 来接收报警信息,然后在 webhook 里面去进行处理,需要发送怎样的报警信息我们自定义就可以
创建一个自定义的钉钉机器人
首先在钉钉群中选择创建一个自定义的机器人:
这里我们选择添加额外密钥的方式来验证机器人,其他两种方式可以忽略,需要记住该值,下面会使用: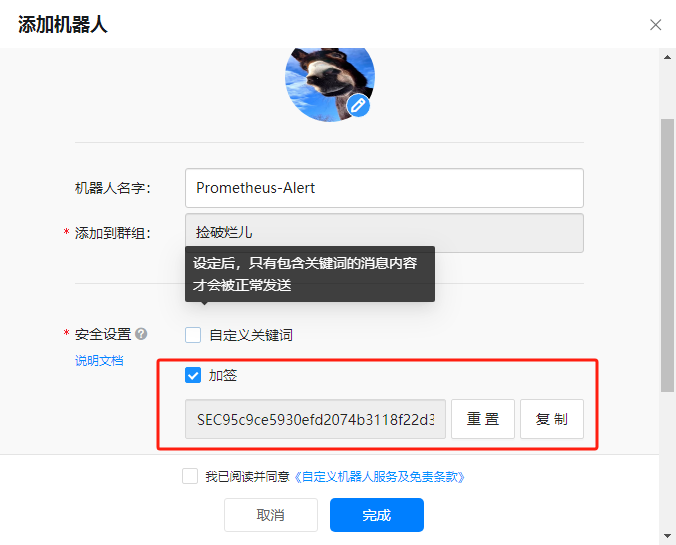
secret:SEC95c9ce5930efd2074b3118f22d32f112ea9a05dccad45923ab587d64921ed47f
创建完成后会提供一个 webhook 的地址,该地址会带一个 acess_token 的参数,该参数下面也会使用: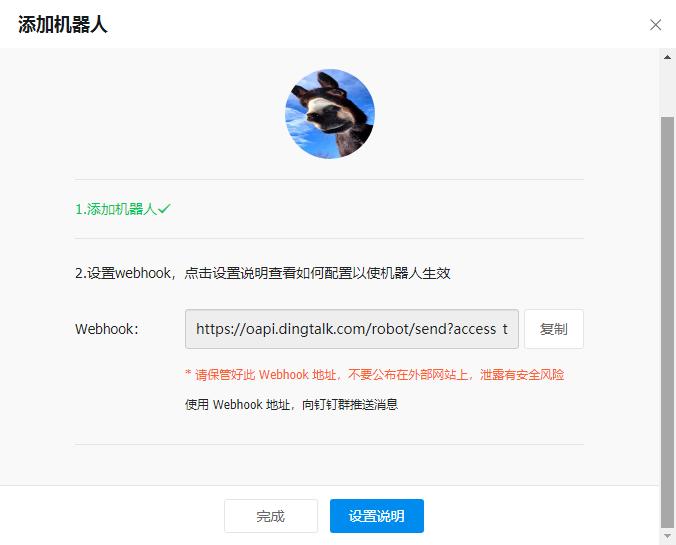
**token:[https://oapi.dingtalk.com/robot/send?access_token=fd38fa44d252da9e230c9477234d8a4025dc96993f02f17547aaaf43130ad009](https://oapi.dingtalk.com/robot/send?access_token=fd38fa44d252da9e230c9477234d8a4025dc96993f02f17547aaaf43130ad009)
安装 prometheus-webhook-dingtalk
timonwong / prometheus-webhook-dingtalk 是Prometheus官方推荐的第三方 Alertmanager Webhook Receiver ,用于支持通过钉钉 DingTalk 发送告警通知。
下载到官方编译的执行程序 prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz (将程序复制到 /opt目录
tar xfz prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 /opt/prometheus-webhook-dingtalk
systemd 方式运行 prometheus-webhook-dingtalk
编辑创建 /etc/systemd/system/prometheus-webhook-dingtalk.service
[Unit]
Description=prometheus-webhook-dingtalk
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/opt/prometheus-webhook-dingtalk/prometheus-webhook-dingtalk --config.file=/opt/prometheus-webhook-dingtalk/config.yml
[Install]
WantedBy=multi-user.target
将配置文件 config.yml 和 template.tmpl ,将这两个文件复制到 /opt/prometheus-webhook-dingtalk 目录下
启动服务
systemctl daemon-reload
systemctl start prometheus-webhook-dingtalk
systemctl enable prometheus-webhook-dingtalk
ss -tnl | grep 8060
编辑 prometheus-webhook-dingtalk 配置文件
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=fd38fa44d252da9e230c9477234d8a4025dc96993f02f17547aaaf43130ad009
# secret for signature
secret: SEC95c9ce5930efd2074b3118f22d32f112ea9a05dccad45923ab587d64921ed47f
# Customize template content
#message:
# Use legacy template
#title: '{{ template "legacy.title" . }}'
#text: '{{ template "legacy.content" . }}'
webhook_mention_all:
url: https://oapi.dingtalk.com/robot/send?access_token=fd38fa44d252da9e230c9477234d8a4025dc96993f02f17547aaaf43130ad009
mention:
all: true
# webhook_mention_users:
# url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx
# mention:
# mobiles: ['156xxxx8827', '189xxxx8325']
修改alertmanager 配置
部署成功后,现在我们就可以给 AlertManager 配置一个 webhook 了,在alertmanager配置中增加一个路由接收器
vim /k8s-data/AlertManager/alertmanager-config.yaml
我们这里配置了一个名为 dingding.webhook1 的接收器,地址为:[http://192.168.18.7:8060/dingtalk/webhook1/send](http://192.168.18.7:8060/dingtalk/webhook1/send),这个地址当然就是上面我们部署的钉钉的 webhook 的接收程序的 Service 地址。
routes:
- receiver: email
group_wait: 10s
group_by: ['instance'] # 根据instance做分组
match:
team: node1
- receiver: dingding.webhook1
group_wait: 10s
group_by: ['instance'] # 根据instance做分组
match:
team: node
- receiver: dingding.webhook.all
group_wait: 10s
group_by: ['instance']
match:
team: node
templates: # 增加 templates 配置,指定模板文件
- '/etc/alertmanager/template_email.tmpl'
receivers: #增加dingding.webhook 和 dingding.webhook.all receivers
- name: 'dingding.webhook1'
webhook_configs:
- url: 'http://192.168.18.7:8060/dingtalk/webhook1/send'
send_resolved: true
- name: 'dingding.webhook.all'
webhook_configs:
- url: 'http://192.168.18.7:8060/dingtalk/webhook_mention_all/send'
send_resolved: true
然后我们可以更新 AlertManager 和 Prometheus 的 ConfigMap 资源对象,更新完成后,隔一会儿执行 reload 操作是更新生效,如果有报警触发的话,隔一会儿关于这个节点文件系统的报警就会被触发了,由于这个报警信息包含一个 team=node 的 label 标签,所以会被路由到 dingding.webhook1 这个接收器中
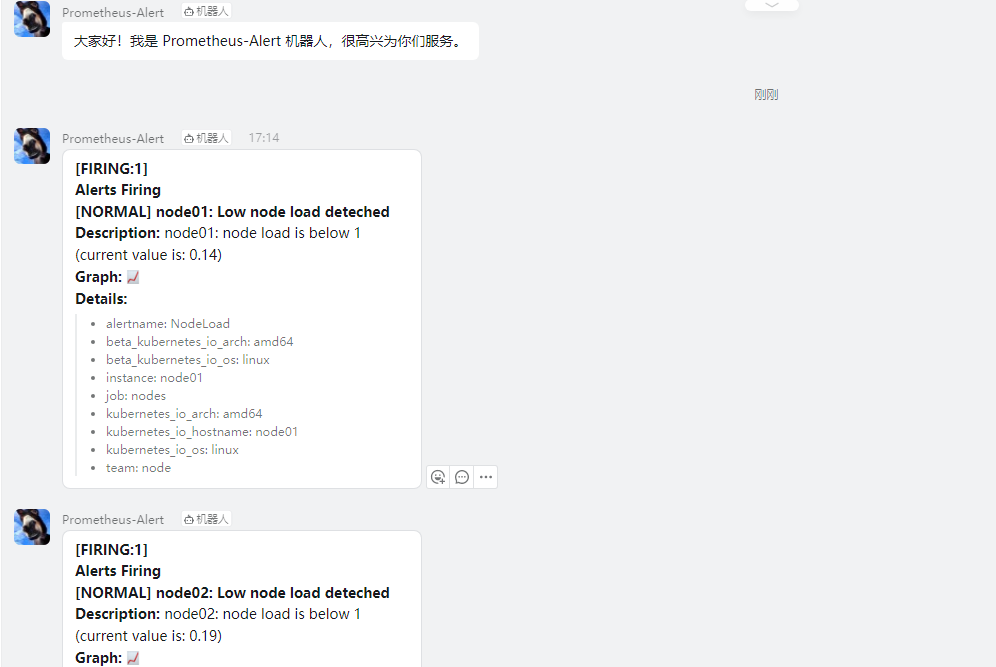
可以看到 POST 请求已经成功了,同时这个时候正常来说就可以收到一条钉钉消息了:
记录规则 Recoding Rule
记录规则(Recording Rule)是 Prometheus 中的一种机制,用于预先计算和存储 PromQL 表达式的结果,以提高查询性能和减少查询负载。当 PromQL 表达式较为复杂且计算量较大时,直接查询可能导致 Prometheus 响应超时或性能下降。通过记录规则,Prometheus 可以在后台进行计算,并将计算结果存储在时间序列数据库中,使得查询时可以直接获取已计算好的结果,而不需要再次执行复杂的计算操作。
记录规则的作用类似于将复杂的查询任务放在后台批处理中完成,使得用户在查询时只需获取预先计算好的结果,而无需关心具体的计算过程。这对于 Grafana 等监控系统的仪表板特别有用,因为仪表板通常需要重复查询相同的表达式,并且这些查询可能会比较复杂。
在 Prometheus 的配置文件中,可以通过rule_files参数定义记录规则规则文件的访问路径,从而告知 Prometheus 加载和执行这些记录规则。通过记录规则,用户可以针对复杂的查询场景进行性能优化,提高查询效率,同时减轻 Prometheus 服务器的负载压力。
rule_files: [- <filepath_glob> ...]
定义规则文件
每一个规则文件通过以下格式进行定义:
groups: [- <rule_group>]
示例规则文件内容如下:
groups:
- name: recording_rules
rules:
- record: instance_http_requests_total
expr: sum(rate(http_requests_total[5m])) by (instance)
在这个示例中,我们定义了一个名为 recording_rules 的规则组,其中包含一个记录规则,名为 instance_http_requests_total。这个记录规则的计算表达式为 sum(rate(http_requests_total[5m])) by (instance),用于计算过去 5 分钟内每个实例的 HTTP 请求总数。计算结果将存储在名为 instance_http_requests_total 的时间序列中。
定义记录规则分组
rule_group 规则组的具体配置项如下所示:
# 分组的名称,在一个文件中必须是唯一的,这个名称用于标识记录规则分组,便于管理和识别。
name: <string>
# 指定评估分组中规则的频率。
#这个参数用于设置记录规则的评估间隔,即规则执行的频率。
#如果不指定,则默认使用全局配置中的评估间隔(global.evaluation_interval)。
[ interval: <duration> | default = global.evaluation_interval ]
rules: #定义记录规则分组中包含的记录规则列表。每个记录规则由一个规则对象(<rule>)表示,可以包含多个记录规则。
[ - <rule> ... ]
与告警规则一致,一个 group 下可以包含多条规则。
每个记录规则对象包含以下字段:
# 指定记录规则的名称,用于标识记录规则生成的时间序列。
record: <string>
# 要计算的 PromQL 表达式,每个评估周期都是在当前时间进行评估的,结果记录为一组新的时间序列,metrics 名称由 record 设置
expr: <string>
# 添加或者覆盖的标签
labels: [<labelname>: <labelvalue>]
根据规则中的定义,Prometheus 会在后台完成 expr 中定义的 PromQL 表达式计算,并且将计算结果保存到新的时间序列 record 中,同时还可以通过 labels 标签为这些样本添加额外的标签。
这些规则文件的计算频率与告警规则计算频率一致,都通过 global.evaluation_interval 进行定义:
global: [evaluation_interval: <duration> | default = 1m]
多个记录规则组案例:
groups:
- name: recording_rules_cpu
rules:
- record: cpu_usage
expr: 100 - (avg_over_time(node_cpu_seconds_total{mode="idle"}[5m]) * 100)
- record: cpu_idle
expr: avg_over_time(node_cpu_seconds_total{mode="idle"}[5m]) * 100
- name: recording_rules_memory
rules:
- record: memory_usage
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100
- record: memory_free
expr: node_memory_MemAvailable_bytes / 1024 / 1024
记录规则示例
比如现在我们想要获取空闲节点内存的百分比,可以使用如下所示的 PromQL 语句查询:
100 - (100 * node_memory_MemFree_bytes / node_memory_MemTotal_bytes)
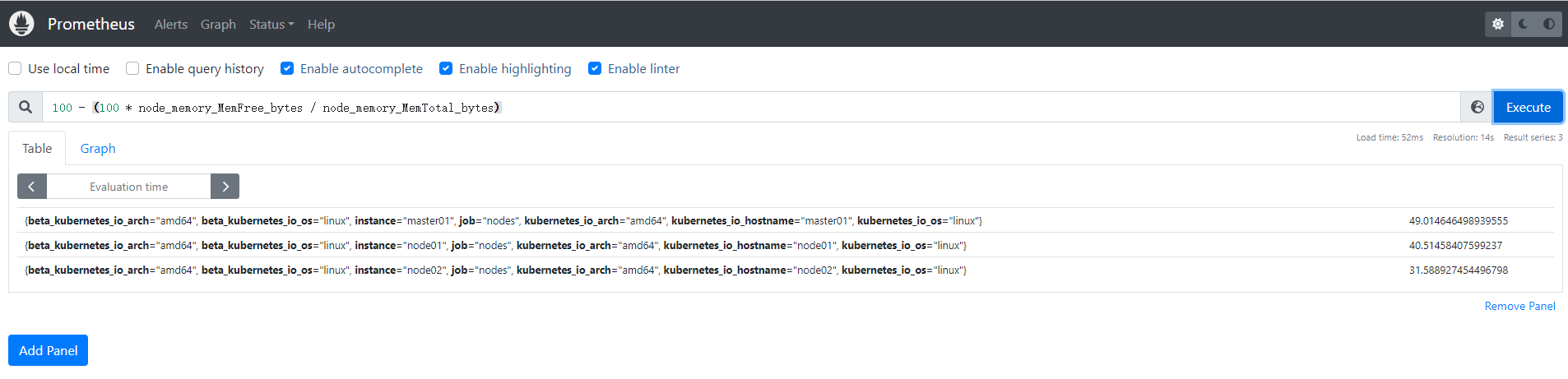
现在我们就可以使用记录规则将上面的表达式重新配置。同样在配置报警规则的 groups 下面添加如下所示配置:
groups:
#记录规则组
- name: recording_rules
rules:
- record: job:node_memory_MemFree_bytes:percent
expr: 100 - (100 * node_memory_MemFree_bytes / node_memory_MemTotal_bytes)
# 其他报警规则组
- name: test-node-mem
rules: # 具体的报警规则
- alert: NodeMemoryUsage # 报警规则的名称
......
这里其实相当于我们为前面的查询表达式配置了一个 job:node_memory_MemFree_bytes:percent 的别名,一般来说记录规则的名称可以使用 :字符来进行连接,这样的命名方式可以让规则名称更加有意义。
更新上面配置并 reload 下 Prometheus 即可让记录规则生效,在 Prometheus 的 Rules 页面正常也可以看到上面添加的记录规则: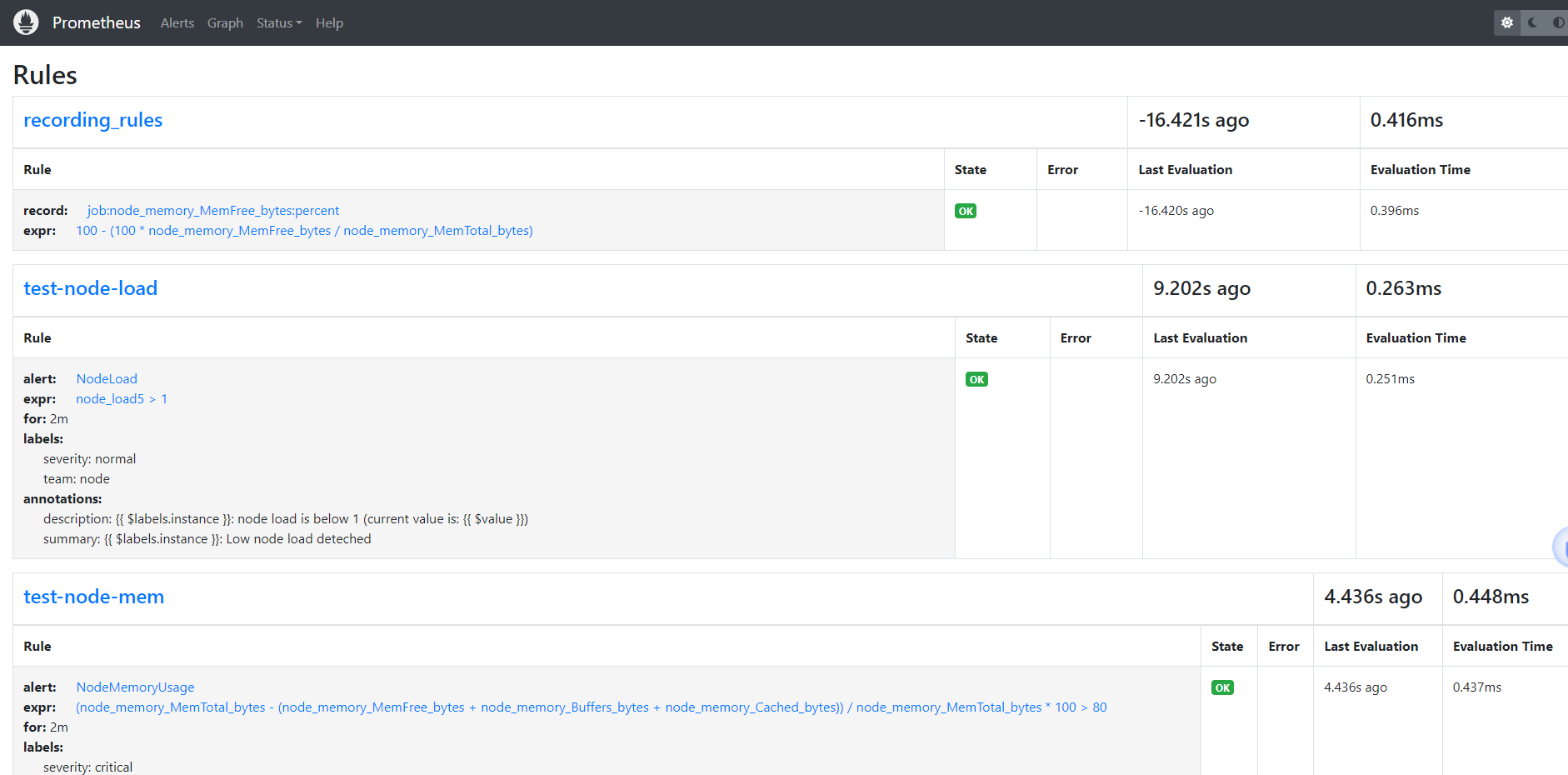
现在我们就可以直接使�用记录规则的名称 job:node_memory_MemFree_bytes:percent 来进行查询了:
由于我们这里的查询语句本身不消耗资源,所以使用记录规则来进行查询差距不大,但是对于需要消耗大量资源的查询语句则提升会非常明显。